L’open data pour la prédiction à maille fine
Alors que les IAs continuent de battre des nouveaux records, une révolution plus silencieuse prend forme dans la sphère Big Data. Il s’agit de celle de l’open data.
Suite à la loi française pour une République numérique de 2016, la France récolte aujourd’hui les fruits de sa stratégie. En effet, la France serait le meilleur élève européen en termes d’open data selon le cabinet Capgemini.
Ces fruits se traduisent par exemple par l’apparition de la Base Nationale Des Bâtiments (BNDB) sortie en Avril 2022. Celle-ci regroupe diverses sources de données autour des bâtiments afin de construire un profil complet pour chaque bâtiment. L’apparition de cette base de données est conditionnée par l’existence préliminaire de multiples sources de données librement accessibles.
Cet article vise à présenter les bases de données open data françaises avec lesquelles nous avons travaillé, la qualité de leurs données ainsi que les applications qui découlent de leur usage.
Les bases open data en France
Diverses sources de données open data sont disponibles aux utilisateurs. Parmi elles :
- La base SIRENE (Système national d'identification et du répertoire des entreprises et de leurs établissements),
- La Base Nationale Des Bâtiments (BNDB),
- Les sources de données en provenance de l’INSEE,
- Les données SYNOP de Météo France,
- La Base Adresse Nationale (BAN).
Cette première partie vise à présenter chacune des bases, la qualité de leurs données et différents cas d’usage qu’on pourrait envisager.
1- La base nationale des bâtiments (BNDB)
Présentation de la BNDB
La BNDB est une base qui a récemment vu le jour. Lancée en Avril 2022 pour les besoins du projet Go-Rénove, elle recense de multiples informations autour des bâtiments. Elle existe en plusieurs versions en fonction du degré de sensibilité des données concernées. La version ouverte contient ainsi des informations de base telles que la surface au sol du bâtiment, sa hauteur, son adresse, l’année de sa construction, son usage, etc…
Des versions plus sensibles sont ensuite réservées au “ayants droit fonciers”, en l’occurrence des organismes publics telles que les collectivités locales. Parmi ces données se trouvent la surface habitable d’un logement, la présence de piscine, le nombre de salles de bains et d'autres données avec un niveau de précision similaire.
Qualité de la BNDB
La BNDB est gérée par le CSTB (Centre Scientifique et Technique du Bâtiment). Ses données sont très complètes avec la vaste majorité de ses colonnes au-dessus de 95% de taux de complétude. 83% des numéros de rue sont présents, c’est un peu mieux que la base SIRENE qui en a 79%. Les autres données sont nettement plus complètes avec un taux de complétion autour de 95%. De plus, lorsqu’il y a ambiguïté (par exemple deux adresses pour le même bâtiment) la BNDB l’indique et liste les différentes adresses possibles. 95% des adresses sont associées avec un unique bâtiment ce qui facilite fortement la jonction de données.
Malgré ces points forts, des incohérences subsistent au sein de la base de données. Certaines adresses peuvent être erronées, des hauteurs et des surfaces au sol de bâtiment peuvent prendre des valeurs absurdes (des bâtiments qui font moins de 2m de haut par exemple). Le géocodage peut lui aussi être défaillant bien qu’une colonne soit prévue à cet effet afin de qualifier la qualité de ce dernier.
Cas d’usage
Différents cas d’usages peuvent être envisagés :
- Référencement des DPE afin d’inciter ou aider à la rénovation thermique des logements (Projet Go Rénove),
- Comparaison des habitudes de consommation d’électricité, de gaz et d’eau en fonction des caractéristiques du bâtiments,
- Propositions de prêts bancaires pour la rénovation des passoires thermiques,
- Les banques et assurances peuvent aussi tirer profit de savoir quels clients sont concernés par la rénovation énergétique pour leur proposer des offres de crédits ou d’assurance correspondant à leur situation,
- Notons également l’émergence d’application B2E (“Business to Employees”) afin de permettre aux entreprises de savoir quels salariés pourraient bénéficier d’une aide pour la rénovation énergétique de leurs logements.
Visualisation 3D des données issues de la BNDB (source: GitBNDB)

2- La base SIRENE
Présentation de la base SIRENE
La base SIRENE recense toutes les entreprises françaises ainsi que leurs différents établissements. Chaque entreprise est identifiée par son numéro SIREN et chaque établissement est identifié par son numéro SIRET, ce dernier étant formé en partie par le numéro SIREN.
Elle recense diverses informations autour des établissements telles que leurs tailles, leurs nombres d’employés, leurs secteurs d’activité… Et chaque établissement est localisé grâce à son adresse.
Qualité de la base SIRENE
La base SIRENE présente de nombreuses colonnes vides. Les données exploitables sont celles de l’adresse, l’activité de l’établissement et les informations essentielles comme le numéro SIRET ou le NIC. La tranche d’effectifs de l’établissement est également utilisable dans une moindre mesure avec un taux de complétion de 14%. Le reste des données ne dépassent pas les 10% de complétude et sont donc difficilement utilisables.
La base SIRENE contient ainsi suffisamment de données pour pouvoir caractériser les établissements actifs et leur type d’activité. Cependant elle recèle également quelques particularités qui rendent son utilisation délicate:
- La base est en partie construite sur la base du déclaratif. N’importe qui peut se déclarer auto-entrepreneur et fonder sa propre entreprise qui figurera à son adresse personnelle. Des établissements “fantômes” font alors leur apparition. La parade à cela est de regarder le nombre d'employés déclaré mais étant donné son taux de complétion de 14% l’impact est limité. Le type d’activité peut alors être utilisé pour ne garder qu’une certaine typologie d’établissements qui ne sont pas susceptibles d’être des établissements “fantômes”, comme par exemple les restaurants.
- La base peut aussi présenter un manque de précision. Sur des données comme le type d’activité ou l’effectif de l'établissement, il n'est pas rare que la réalité observée soit différente. Ainsi, les photos Google Maps à différentes dates ne donnent pas toujours raison à cette base: certains établissements n’existent pas, d'autres sont sous-dimensionnés ou ne correspondent pas à l’établissement observé. Il serait intéressant de comparer les informations de la base SIRENE avec des informations issues d’une autre source de données, comme celles issues des APIs mises à disposition par Google Maps.
Cas d’usage
On peut envisager différents usages pour la base SIRENE :
- Analyse des activités déjà présentes dans un quartiers pour cibler l’implantation d’un nouvel établissement (par exemple choix du quartier pour implantation d’un nouveau restaurant),
- Ciblage de clients professionnels pour leur proposer des contrats d’assurance adaptés à leur emplacement (risque d’inondation, de manifestations,...),
- Pour l’ensemble des entreprises B2B, cette base permet de mieux connaître leurs clients en croisant leursdonnées internes avec les données SIRENE.
3- Les bases de données INSEE
Présentation des base de données diffusées par l’INSEE
L’INSEE diffuse de très nombreuses bases de données. Celles-ci comportent diverses statistiques nationales repérées à différentes échelles, la plus précise étant celle de l’IRIS (Ilot Regroupé pour l’Information Statistique). Il s’agit d’un découpage infra communal établi en 1999 afin de diffuser le recensement de la population, chaque IRIS vise une population approximative de 2000 personnes.
On retrouve des données classiques de recensement mais aussi d’autres statistiques intéressantes comme le revenu médian, la répartition des âges, la répartition des résidences secondaires/principales, le taux de chômage,etc.
Ces données, trop nombreuses pour être listées ici, permettent par exemple d’établir un contexte socio-économique pour un bâtiment comme savoir si ce dernier est implanté dans un quartier riche ou non. Qualité des bases de données de l’INSEE
Concernant les données en provenance de l’INSEE, nos diverses explorations ont montré que celles-ci ont de très bons taux de complétion. Par exemple, les données sur la population des IRIS affichent un taux de complétion de 100%. En règle générale, une grande majorité des colonnes avec lesquelles nous avons travaillé ont un taux de complétion qui dépasse les 99%. Les données INSEE semblent donc être de très bonne qualité.
Cependant, étant donné la multiplicité des sources disponibles, il est possible d’imaginer l’existence de bases de données dont la qualité serait moindre, mais cela reste à prouver.
Cas d’usage
- Ciblage de zone pour implanter de nouveaux magasins (boutique de luxe dans un quartier riche, etc.),
- Adaptation des installations publiques en fonction de la répartition des tranches d’âges présentes dans le quartier.
4- La base de données météorologiques SYNOP
Présentation de la base de données
La base SYNOP contient des données d'observations issues des messages internationaux circulant sur le système mondial de télécommunication de l’Organisation Météorologique Mondiale. Divers paramètres mesurés sont disponibles depuis Janvier 1996 jusqu’à aujourd’hui comme la température, la pluviométrie, l’humidité, la direction et force du vent ainsi que la pression atmosphérique. Elle contient également des paramètres observés depuis la surface terrestre : temps sensible, description des nuages, visibilité, etc. D’autres paramètres sont également accessibles suivant les régions, comme par exemple la hauteur de neige.
Qualité des données de la base SYNOP
Les données SYNOP affichent de bons taux de complétion supérieur à 97%, sur les mesures météorologiques “classiques” (température, humidité, pression, précipitations, etc.). D’autres mesures de phénomènes plus anecdotiques présentent des taux de complétion plus faibles mais ne sont pas signe d’une mauvaise qualité de données mais de leur rareté (présence de nuage ou de neige par exemple).
Notre étude se portant sur des données récentes (à partir de 2019), il se pourrait qu’une partie des données ne soient pas disponibles pour des années plus anciennes.
Cas d’usage
- Modélisation de consommation d’électricité, gaz et eau,
- Optimisation des plans de rénovations de bâtiments,
- Modélisation de vente de vêtements de saison.
Distribution géographique des stations météo en France (source: data.gouv)

5- La Base Adresse Nationale (BAN)
Présentation de la BAN
La BAN a vu le jour le 15 avril 2015 grâce à l’alliance de divers acteurs:
- l'IGN
- Le Groupe La Poste
- OpenStreetMap France (association loi de 1901)
- La mission Etalab (service du Premier Ministre chargé de l'Open Data en France)
Elle a pour vocation de recenser l’ensemble des adresses du territoire français avec notamment des fins de normalisation. Elle contient actuellement plus de 25 millions d’adresses sur le territoire français.
La BAN est également accompagnée d’une API qui permet de récupérer l’adresse normalisée à partir d’un champ adresse qui ne l’est pas. Ainsi elle permet de transformer l’adresse “21 R Berri Paris” en “21 rue de Berri 75008 Paris” ce qui ouvre un certain nombre de possibilités que nous détaillerons juste après.
La BAN contient également des coordonnées ce qui permet de repérer spatialement les adresses. Cela permet par exemple de savoir dans quelle IRIS se trouve une adresse (Ilôts Regroupés pour l’Information Statistiques de l’INSEE).
Qualité des données de la BAN
A travers nos diverses manipulations de la BAN nous avons pu apprécier la fiabilité de cette base ainsi que celle de son API. Avec de très bons taux de complétion, elle répond à la plupart des attentes.
Quelques soucis de géocodage et d’adresses mal écrites existent cependant, il arrive par exemple qu’on n’arrive pas à localiser une adresse à travers Google Maps ou dans nos bases de données. Certaines adresses existent en différentes versions également. Ces défauts semblent concerner des territoires ruraux où la densité de population est plus faible. La qualité des adresses est supérieure dans les zones urbaines.
Cas d’usage
- Jonction de différentes bases de données par le moyen de l’adresse,
- Normalisation des adresses au sein d’une base de données afin de maximiser le taux d’envoi des courriers,
- Géocodage des adresses à des fins de représentation ou d’analyses géographiques.
Conclusions sur les base de données existantes en France
En conclusion de cette partie, les bases de données aujourd’hui présentes en France sont diverses et variées. Elles couvrent un large champ d’informations différentes ce qui leur donne de multiples applications. Nous avons couvert dans cet article une partie des bases de données accessibles en open data. De nombreuses autres sources de données sont accessibles sur data.gouv et couvrent de nombreux autres périmètres. D’autres acteurs de l’open data participent également à la diffusion de l’open data comme OpenDataSoft.
Concernant la qualité des données ouvertes, elle peut varier d’une source à l’autre. Cette variation de qualité dépend de l’organisme chargé de la gestion de ces données mais aussi de la nature de ces données. Ainsi l’INSEE peut produire des données de qualité sur des statistiques macroéconomique mais peut aussi produire des données de qualité moindre comme pour le cas de la base SIRENE qui dépend en grande partie de la justesse des déclarations des entreprises concernées.
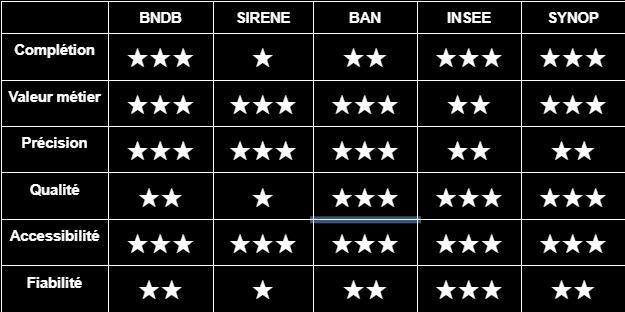
Nous proposons en synthèse de cette partie un tableau récapitulatif sur les qualités et les défauts des différentes bases de données disponibles.
La construction de profils augmentés à l’aide de la jonction par adresse
Grâce à l’API de la BAN, l’adresse n’est plus un simple champ texte rempli au gré des majuscules et autres erreurs de frappe mais devient une donnée normalisée. Il est ainsi possible d’effectuer des rapprochements entre différentes bases de données sur leur adresse. A noter cependant que les adresses se doivent d’être un minimum complètes et de comprendre notamment le numéro de rue. Un des premiers freins à l'utilisation de l’adresse comme moyen de jonction est en effet les numéros de rue manquants.
Ainsi, on peut regrouper autour d’une adresse toutes les données présentées précédemment, à savoir :
- Les données bâtiment,
- Les données SIRENE sur les établissements,
- Les informations du quartier et de la commune dans lequel se trouve l’adresse (statistiques socio-démographiques),
- Les données météorologiques SYNOP,
- Les données calendaires (vacances, jours fériés,...),
- Et toute autre donnée interne à une entreprise qui est repérée par une adresse.
Schéma de l’organisation des données ouvertes autour de l’adresse
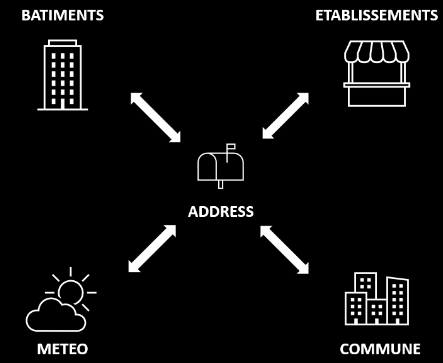
La jonction au niveau de l’adresse permet de joindre tous les niveaux géographiques de du bâtiment jusqu’au données de la commune.
On obtient alors un ensemble de données qui décrit de manière complète le contexte dans lequel évolue chaque logement. Ce contexte nous permet ensuite d’expliquer ou de modéliser une variable cible, par exemple la consommation d’électricité, en prenant en compte les interactions entre différentes variables. Les techniques statistiques plus poussées comme les algorithmes de Machine Learning deviennent en conséquence plus adaptées en raison de la complexité des ensembles de données constitués. Elles permettent de révéler et de quantifier les relations entre différents phénomènes. Par exemple, la combinaison entre une température élevée et une grande surface habitable peut résulter en une augmentation significative de la consommation d’électricité d’un foyer.
Enfin, pour certains organismes publics, l’accès à ces données augmentées permet de mieux gérer les installations d’un territoire et de rendre plus précis certains contrôles autour des déclarations faites par les citoyens, notamment les déclarations autour des caractéristiques du logement et du foyer. De plus, les organismes publics ayant accès à des versions plus précises des données existantes, ils peuvent tirer plus de valeurs ajoutées de l’utilisation de ces données.
Conclusion
L’open data devient de plus en plus mature en France. Il est aujourd’hui possible d’aisément construire des objets relativement complets et précis sur tout le territoire français. Certains acteurs utilisent déjà la richesse des ces données comme namR qui les combine avec des données en provenance de partenaires ainsi que des traitements à base d’Intelligence Artificielle (en utilisant des images satellites par exemple) afin de construire des profils de bâtiments les plus complets possible.
Chez Sia Partners nous partageons la conviction selon laquelle l’open data est une force que nos clients peuvent utiliser pour de nouvelles applications à forte valeur ajoutée. L’open data est un nouveau levier qui va continuer à évoluer et que les entreprises peuvent utiliser pour enrichir leurs panels de données. Dans cette optique, Sia Partners développe en interne une veille continue sur l'Open Data et la mise en place d’un entrepôt de données Open Data prêt à l'usage afin d'apporter cette valeur aussi rapidement que possible à nos clients.


