Tirer parti de l'IA pour automatiser sa veille industrielle : un avantage concurrentiel
Illustration sur le secteur de l’hydrogène : comment l'expertise IA combinée aux expertises UX / WebDev permet aux experts Hydrogène de Sia Partners de rendre plus efficace la veille du secteur de l'Hydrogène
Un peu de contexte
Dans de nombreux secteurs en évolution, la surveillance de l'environnement réglementaire / concurrentiel / sectoriel est essentielle. Elle permet aux départements Stratégie et Marketing de mieux anticiper les besoins futurs de l'industrie et ainsi d’optimiser la proposition de valeur de l'entreprise.
Ce défi est relevé par une équipe d'experts au sein de l'équipe Energie de Sia Partners (le 'Club Hydrogène') qui publie une newsletter mensuelle sur le secteur de l’hydrogène. Cette newsletter fournit des actualités, des points de vue et des opinions liés au secteur. Le Club H2 doit être en veille permanente sur les nouveaux projets et les nouvelles réglementations à travers le monde.
L'écosystème hydrogène est actuellement en plein essor et de nombreux articles sont publiés quotidiennement par des sources très variées, aussi bien des journaux généralistes que des pure-players de l'actualité H2. Pour surveiller toutes ces sources, l'équipe a expérimenté différents outils, notamment des agrégateurs de flux RSS. Cependant, cette solution ne correspondait pas à leurs besoins car les différents articles n'étaient ni hiérarchisés ni classés. Il était donc difficile :
- d’extraire les informations clés du bruit H2 en ligne
- d’identifier les grandes tendances du secteur
- de suivre des sources publiées dans différentes langues
Les experts H2 souhaitaient disposer d'une solution permettant une véritable veille sur l'actualité H2 :
- Accès à un historique trié de l'actualité H2 avec des fonctionnalités de recherche
- Aperçu rapide des principales informations quantitatives (Subvention, Capacité électrique, etc.)
- Aperçu des principaux acteurs agissant sur le terrain (Pays, Entreprises, Organisations internationales)
- Traduction automatique en anglais de toutes les sources
- Tableau de bord intuitif pour identifier rapidement les sujets
Solution
Dans l’incapacité de trouver un outil correspondant à ses besoins sur le marché, le club H2 a pu s'appuyer sur l'expertise de la Business Line Data Science de Sia Partners et sur sa plateforme d'accélération pour industrialiser rapidement des solutions sur mesure : Heka. Après plusieurs ateliers, les experts en hydrogène et data scientists de Sia Partners ont proposé la solution suivante : une application Web qui collecte automatiquement plusieurs sources avant de tirer parti d’algorithmes NLP (Natural Language Processing) pour extraire automatiquement les informations clés de l'actualité.
Comme le besoin Métier sous-jacent n'est pas spécifique à l'industrie de l'hydrogène, la solution a été conçue pour être agnostique du secteur de l'hydrogène dès sa conception et peut ainsi être utilisée pour n'importe quel domaine.
SentiNews
Scraping & Traduction
L'équipe Hydrogène a identifié une liste de 39 sources pertinentes qui permettent d'avoir une bonne représentation de l'actualité liée à l'hydrogène. Les nouveaux articles et leur contenu doivent être collectés tous les soirs car les experts surveillent l'actualité de façon quotidienne. Les articles, provenant de sources de langues très variées, doivent également être automatiquement traduits en anglais.
Extraction d’information
Les informations clés suivantes doivent être extraites de chaque article :
- Chiffres clés (dates, montant financier, capacité, durée, etc.)
- Pays concernés
- Acteurs (Entreprises et organisations) mentionnés dans l'article
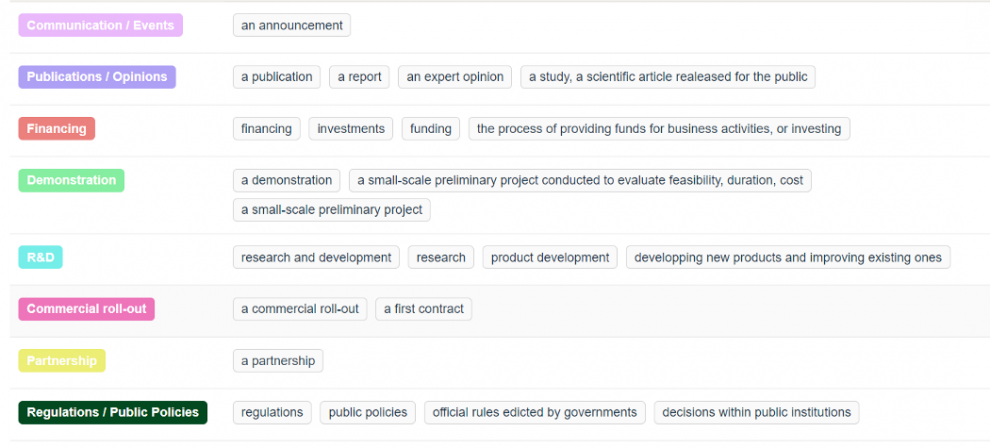
De plus, tous les articles doivent être classés selon les axes suivants :
- Position au sein de la chaîne de valeur de l'hydrogène (ex. Production, Stockage, Transport, etc.)
- Thème de l'article (ex. Annonce de partenariat, Régulation, Financement, etc.)
Le marché H2 évoluant rapidement, les axes de classification et les informations clés à extraire doivent être facilement modifiables par des utilisateurs non techniques via l'application Web.
Application Web
Les articles et analyses sont accessibles sur une Application Web appelée ‘Strategic Watch’. Cette application web doit mettre à disposition :
- Une fonctionnalité de recherche qui simplifie le suivi et l'analyse en permettant :
- d’accéder aux données historiques
- de filtrer par organisation, date, sujet, etc.
- de fournir une recherche textuelle dans tous les articles
- Une vue agrégée affichant les informations clés extraites de chaque article dans un format tableau
- Une vue détaillée permettant aux utilisateurs de lire directement l'article dans l'application, avec les principales informations mises en évidence dans le texte.
L'application Web doit également inclure une page de paramétrage où les utilisateurs peuvent modifier le type d'informations qu'ils souhaitent extraire.
Approche technique
Utilisation de Heka
Au cœur de la stratégie Consulting 4.0, Heka est la plateforme d'intelligence artificielle industrielle de Sia Partners. Elle est composée de toutes les briques techniques nécessaires à la réalisation de projets de Data Science et permet un déploiement rapide de projets de Machine Learning ou Deep Learning de tous types : reconnaissance vocale ou d'image, traitement du langage naturel, etc… Heka garantit un time-to-market rapide, de l’idéation au POC et du POC à l'industrialisation, ainsi que l'évolutivité et la robustesse des solutions d'intelligence artificielle.
Nous avons donc utilisé Heka comme plateforme sous-jacente à l'application Web et à ses algorithmes d'IA.
Le modèle de données de l’application repose sur une combinaison de bases de données MongoDB et ElasticSearch pour permettre de réaliser de façon efficace des filtres et des recherches textuelles dans les articles scrappés.
Indépendant du domaine d’application
Même si ‘Strategic Watch’ a été initialement imaginé pour un cas d'utilisation lié à l’hydrogène, l’ensemble des choix techniques ont été faits afin que l’outil puisse servir pour n’importe quel autre domaine. Par conséquent, toutes les briques structurelles de l'application sont indépendantes du secteur de l’hydrogène.
Le pipeline de données est composé de deux briques différentes : Scrapping et NLP (Natural Language Processing / Traitement automatique du langage naturel), ce dernier étant composé de deux tâches différentes, la classification en thèmes et l’extraction d’entités.
Classification en thèmes
Pour accomplir cette tâche, la classification supervisée aurait pu être une solution adaptée. Il était tout à fait envisageable de collecter un grand nombre d'articles, et de demander à l'équipe Hydrogène d’annoter ces articles pour avoir un jeu de données d’entraînement et ainsi développer un modèle. Cependant, nous avions besoin que notre modèle fonctionne quel que soient les thématiques d’intérêt, puisque l'utilisateur a la possibilité d'ajouter de nouveaux axes d’analyses ou de modifier les thèmes existants au sein de ces axes. Il était donc inconcevable d’effectuer une nouvelle annotation et un nouvel entraînement du modèle à chaque fois qu’un thème ou un axe était créé ou modifié. Ainsi, notre défi principal n’était pas de collecter une quantité de données suffisante, comme c’est souvent le cas en Machine Learning, mais plutôt de développer une solution qui soit performante quelles que soient les évolutions et besoins futurs. L'idée d'une classification supervisée a donc été écartée.
Nos data scientist ont ainsi choisi d'utiliser un modèle de zero-shot-classification. HuggingFace fournit des modèles de zero-shot-classification capables d'effectuer des prédictions sans données labellisées. Ces modèles bénéficient de capacités de NLI (Natural Language Inference) pour effectuer des classifications de textes. Étant donné deux entrées - une prémisse et une hypothèse - le modèle prédit un score en fonction de la concordance des hypothèses avec la prémisse (par exemple « Ce texte parle d'un partenariat » pour évaluer le sujet Partenariat). Cette méthode fournit de moins bonnes performances qu’une approche supervisée, mais est beaucoup plus polyvalente.
Le choix des mots-clés utilisés dans les hypothèses est crucial pour atteindre de bons niveaux de performance pour la tâche de classification. Notre équipe Data Science a travaillé aux côtés des experts métiers pour choisir ces termes de façon optimale, et partager avec eux les meilleures pratiques puisqu’ils auront la possibilité d'ajouter eux-mêmes de nouveaux sujets lorsque l'application sera en production.
Extraction d'entités
L'équipe Hydrogène était également très intéressée par la possibilité d'extraire des entités spécifiques des articles, pour identifier par exemple quels pays et acteurs étaient mentionnés et quels étaient certains des chiffres clés.
Pour identifier ce type d'informations, nous avons utilisé l'algorithme d'extraction d'entités nommées de Spacy. Cet algorithme combine un réseau de neurones convolutifs profonds avec des connexions résiduelles, des embeddings de mots utilisant des features de sous-mots et des embeddings “Bloom”, et une approche basée sur les transitions afin de fournir des résultats précis et efficaces. Il détecte les entités nommées suivantes :

Les experts Hydrogène souhaitaient avoir accès aux lieux (LOC), organisations (ORG), dates (DATE), heures (TIME), montant monétaires (MONEY), chiffres (CARDINAL), pourcentages (PERCENT), et quantités (QUANTITY).
De plus, il était important d'avoir des entités plus spécifiques sur les « quantités » afin de relever les chiffres sur des capacités et coûts énergétiques, ou encore des puissances. Nous avons donc défini des expressions régulières personnalisées qui détectent ces nouvelles entités et priment sur les prédictions de Spacy.
Enfin, des méthodes de post-traitement spécifiques ont été développées pour harmoniser les entités, telles que :
- Filtre des dates trop proches de la date de publication de l'article pour éviter les entités du type « mardi dernier » et privilégier les dates clés
- Géolocalisation des lieux détectés pour extraire le nom du pays
- Traitement des noms d'organisations pour faire le lien entre des termes tels que « l'Union européenne », « l'Union européenne », « l'UE ».
Conclusion et prochaines étapes
La solution est désormais utilisée quotidiennement par 10 experts de l'équipe Energie et les aide à rédiger facilement la newsletter mensuelle H2. À ce jour, plus de 1 600 articles ont été scrappés et traduits avec les entités et les thématiques extraites.
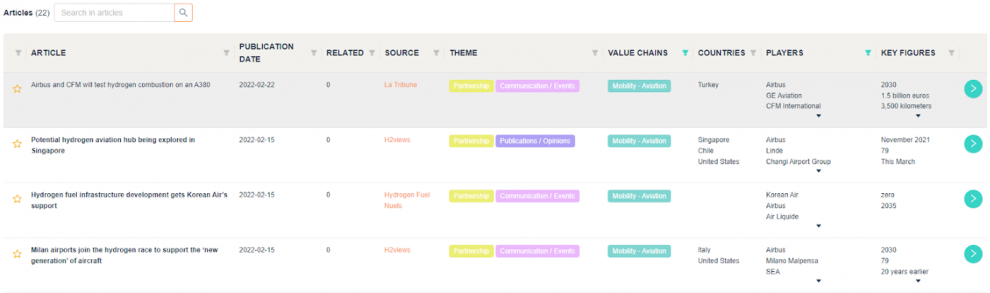
Par exemple, la solution permet de rechercher rapidement toutes les actualités liées à l'utilisation d’hydrogène dans l'aéronautique et impliquant Airbus :
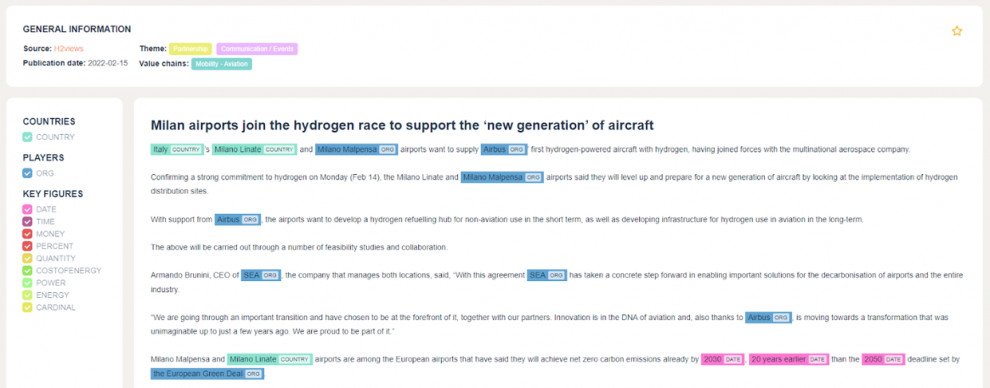
Si un article semble intéressant pour les experts, ils peuvent directement cliquer dessus et avoir une vue détaillée avec les principales informations en surbrillance.
Afin de continuer à améliorer la solution, une fonctionnalité de newsletter est actuellement en cours de développement. Elle permettra aux utilisateurs de recevoir par email soit l’ensemble des articles scrappés liés à un sujet/organisme spécifique, soit une sélection des articles les plus importants pour chaque sujet à une fréquence définie.
Les prochains développements permettront aussi à plusieurs utilisateurs ayant différents domaines d'expertise d'utiliser une même plateforme grâce à des permissions basées sur des rôles. Ainsi, un même utilisateur pourrait par exemple avoir accès à des veilles séparées sur les secteurs de l’hydrogène et du nucléaire, extraites de sources personnalisées et définies par différents experts.
L’outil ‘Strategic Watch’ a déjà été adapté et est actuellement utilisé par une municipalité qui a besoin de surveiller l’actualité autour de la thématique du Design. La solution a pu être utilisée telle quelle grâce à l'architecture indépendante de la notion d'hydrogène - le seul paramètre à adapter était la liste des sources à scrapper.


