Topic modeling : un processus de bout en bout pour extraire les thèmes d’un corpus de textes courts
Cet article fait suite au précédent article sur le topic modeling qui présentait un benchmark détaillé des différentes techniques de topic modeling appliquées à un cas business. Ici, nous utilisons le topic modeling sur n'importe quel cas business en minimisant les ressources humaines nécessaires.
Introduction
Vous trouverez notre précédent article sur le topic modeling ici.
Rappelons d'abord ce qu'est le topic modeling et pourquoi nous en avons besoin. Le topic modeling est une tâche de NLP visant à extraire les sujets intéressants d'une importante collection de documents. Alors que la lecture du corpus complet nécessiterait une quantité massive de temps et de ressources humaines, l'idée du topic modeling est de rendre automatique une grande partie de ce travail.
Tout comme dans l'article précédent, nous allons également nous concentrer sur l'extraction de sujets à partir des commentaires récupérés sur internet d’agences postales et nous allons appliquer le processus complet sur ce cas. Ce processus contient trois étapes principales :
- Une étape de prétraitement des données (automatique)
- Un réglage des hyperparamètres pour plusieurs modèles basé sur l'optimisation Bayésienne (automatique)
- Une analyse approfondie des résultats (semi-automatique)
Prétraitement des données
L'ensemble de données contient environ 30 000 commentaires de courte longueur. Après avoir supprimé les stopwords (mots vide de sens), il reste 33 782 mots uniques dans le jeu de données complet. Il existe quelques étapes de prétraitement standard pour tout projet NLP :
- Les textes sont mis en minuscules.
- La ponctuation et les chiffres sont supprimés.
- Le texte est lemmatisé (cela signifie que nous ne gardons que la racine de chaque mot dans l'ensemble de données).
- Enfin, les mots vides (mots sans signification) sont supprimés de l'ensemble de données.
Voici un exemple de document prétraité:
Document original:
"Même si la traçabilité n'est pas aussi précise qu'avec Chronopost (pas le même tarif !!!)les envois sur la polynésie sont toujours dans des délais correct, je n'ai eu à ce jour aucun problème avec eux."
Document prétraité :
“si être aussi précise chronopost tarif envoi être toujours délai correct avoir avoir jour aucun problème”
De nombreuses bibliothèques Python NLP proposent des fonctions pour gérer ces étapes classiques de prétraitement. Pour nos expériences, nous avons travaillé avec OCTIS. Une bibliothèque NLP spécialisée dans la modélisation de sujets.
Métrique
Cohérence
Comme nous l'avons mentionné dans un article précédent, la cohérence est une métrique classique pour évaluer les modèles thématiques. Il existe plusieurs mesures de cohérence, mais elles suivent toutes la même structure. La cohérence est destinée à mesurer la cohérence des documents au sein d'un sujet. Elle a la structure suivante :
img

Un corpus de référence externe peut nous aider à créer un calcul de probabilité sur les mots.
Étant donné deux mots d'entrée w et w', nous pouvons utiliser cette probabilité pour calculer la probabilité conditionnelle d'un document contenant w' étant donné le fait qu'il contient w. Cette probabilité conditionnelle peut être utilisée pour construire une mesure de confirmation directe (de nombreux choix sont possibles pour construire cette mesure).
Considérons ensuite un ensemble de mots W (un topic), et un mot w appartenant à W. En calculant la somme des mesures de confirmation directe entre w et tous les autres mots w’ de W on peut construire la mesure de confirmation indirecte . Ça revient en fait à utiliser tous les mots w' de l'ensemble W comme intermédiaires pour calculer le score de w.
Enfin, les scores de tous les mots dans W peuvent être agrégés pour calculer un unique score de cohérence pour W.
Dans cette analyse, nous avons choisi de travailler avec le score de cohérence CV qui n’est rien d’autre que la métrique présentée ci-dessus avec des choix spécifiques pour les deux mesures de confirmation et pour la fonction d'agrégation.
Diversité
Une autre métrique importante est la diversité. Elle vise à mesurer dans quelle mesure le topic model est large et capable de capturer autant d'informations que possible. Il existe essentiellement deux types de diversités, certaines sont basées sur les tokens de mots considérés comme des ensembles, et d'autres sont basées sur des distributions de probabilité.
La mesure la plus utilisée est la similarité Jaccard moyenne (JS). Elle est basée sur le ratio de mots communs entre les sujets : entre le sujet t1 and t2:
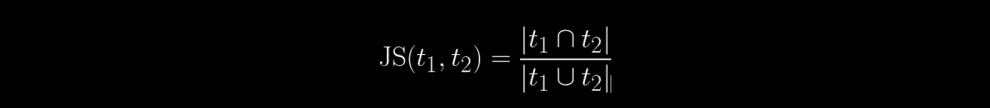
Nous obtenons une diversité en prenant 1 - JS(t1, t2)
Une autre métrique basée sur les tokens de mots considérés comme des ensembles est le calcul du pourcentage de mots uniques parmi les 10 premiers mots de tous les sujets, c'est la métrique choisie pour nos expériences.
Les métriques basées sur les probabilités utilisent généralement la divergence KL (divergence de Kullback-Leibler) pour comparer la distribution des sujets sur les mots

Il y a un équilibre à trouver entre la cohérence et la diversité, une réflexion spécifique est nécessaire afin d'estimer l'importance relative de ces deux métriques.
Métriques avec des sujets prédéfinis
Selon le cas d'utilisation, une liste de sujets peut être prédéfinie. Dans cet article, nous nous concentrons sur les métriques et l'optimisation sans sujets prédéfinis, cette section est destinée aux informations génériques sur la modélisation des sujets.
La liste peut être complète ou partielle. L'objectif est de comparer une liste de sujets trouvés par les modèles et de la noter par rapport à la liste de sujets prédéfinis. Dans ce cas, il existe des métriques spécifiques qui peuvent être utilisées pour aborder ce cas. Deux d'entre elles seront décrites dans la section suivante : Cosine similarity and Triangle area Similarity - Sector area similarity (TS-SS)
Cosine similarity
Cosine similarity est une métrique bien connue et utilisée dans de nombreuses applications dans le cadre des tâches NLP. Elle mesure la similarité entre les vecteurs.
Étant donné deux vecteurs A et B, la similarité cosinus cos(θ) est donnée par la formule suivante :
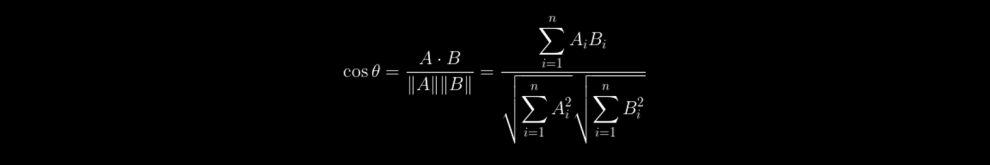
La valeur est comprise entre 0 et 1 car elle correspond au cosinus de l'angle entre les vecteurs. Plus le score est proche, plus les vecteurs sont similaires.
Un inconvénient majeur de la similarité en cosinus est qu'elle ne prend pas en compte la magnitude du vecteur. La métrique suivante TS-SS inclut cette magnitude
Triangle area Similarity - Sector area similarity (TS-SS)
Comme décrit dans cet article, cette métrique combine la similarité cosinus et la distance euclidienne.
Étant donné deux vecteurs A et B, la première partie de la métrique est la similarité TS(A,B).
TS est donnée par la formule suivante :
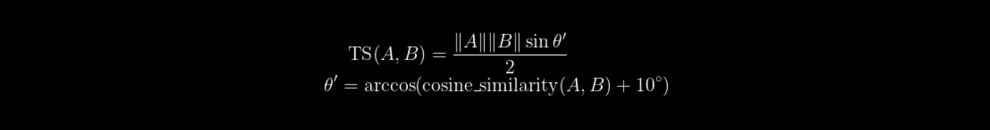
Nous utilisons en général 10 degrés comme minimum pour faciliter les calculs.
Et la similarité SS est donnée par :
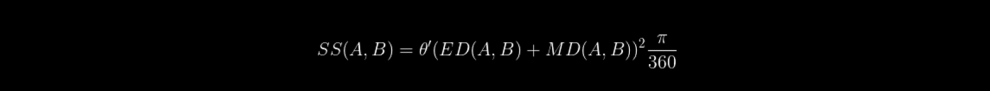
où MD est la valeur absolue de la différence entre A et B, ED est la distance euclidienne entre A et B.
Enfin, voici la métrique finale :
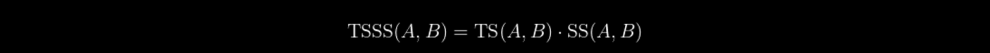
TSSS varie de 0 à une valeur positive infinie. Contrairement à la cosine similarity, plus la TSSS est proche de 0, plus les vecteurs sont proches.
Comparaison : Cosine Similarity and TS-SS

Enfin, d'après notre expérience en topic modeling, TS-SS est le meilleur moyen de comparer les modèles entre eux en raison de sa forte sensibilité à la variation de la pertinence des sujets
Étape d'optimisation
Une fois les données prétraitées, il est temps d'entraîner les modèles et d'optimiser les hyperparamètres. Pour être complémentaire avec les articles précédents sur le topic modeling, nous avons choisi de nous concentrer sur trois modèles basés sur les réseaux de neurones : NeuralLDA, ProdLDA et CTM. Ces modèles sont dérivés du modèle classique LDA (Latent Dirichlet Allocation), mais sont couplés à des réseaux de neurones profonds afin de profiter de leurs performances.
Dans nos expériences, nous avons choisi la bibliothèque Python Optuna pour effectuer l'optimisation. Cette bibliothèque met en œuvre des techniques d'optimisation Bayésienne pour proposer itérativement de nouveaux paramètres maximisant une métrique donnée.
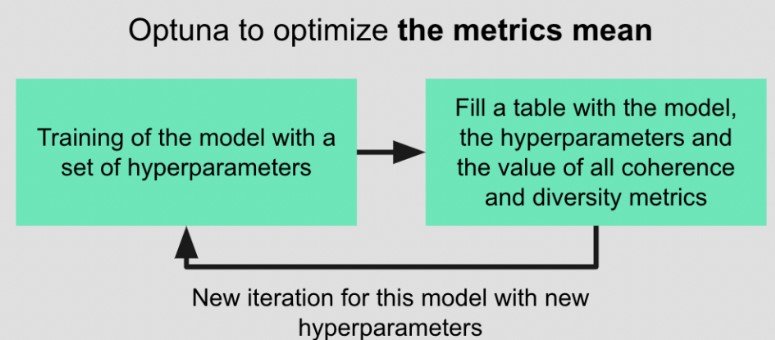
Ici, nous essayons de maximiser la moyenne entre la diversité et la cohérence. Nous avons décidé d'attribuer un poids égal aux deux métriques car notre cas n'apporte pas de conviction forte sur la métrique sur laquelle nous devions nous concentrer. Dans le cadre d'une étude de cas, il serait nécessaire d'essayer d'évaluer cet équilibre plus précisément et d'attribuer des poids différents aux deux métriques.
Pour chaque modèle, l'idée est de faire tourner Optuna pour réaliser plusieurs itérations (environ 500). A chaque itération, Optuna propose des valeurs pour tous les hyperparamètres puis un modèle est entraîné avec ces hyperparamètres. Les métriques moyennes sont envoyées à Optuna et les performances complètes du modèle sont sauvegardées dans un tableau de résultats avec les hyperparamètres.
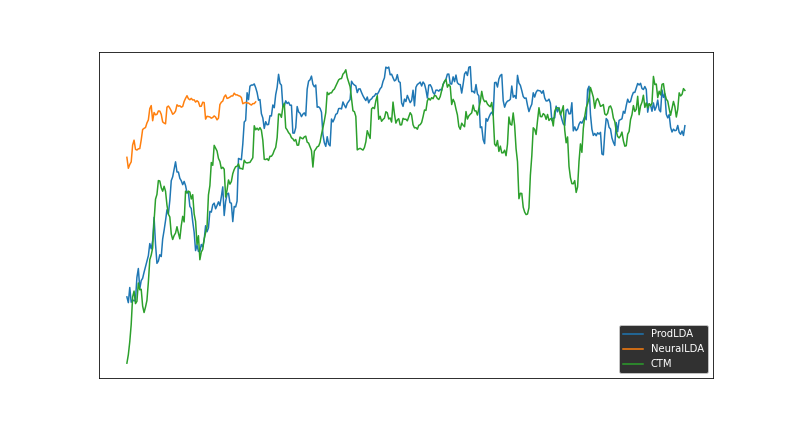
Après l'exécution de chaque modèle, des vérifications de convergence doivent être effectuées. Sur ce graphique, la métrique optimisée par Optuna (moyenne entre diversité et cohérence) est tracée pour chaque modèle au fil des itérations. En raison de performances médiocres (valeur de cohérence très faible, principalement des topics vide de sens), nous avons décidé d'arrêter les expériences NeuralLDA et de nous concentrer sur ProdLDA et CTM. Par exemple, le modèle NeuralLDA proposait plusieurs topics proches de celui ci-dessous :

Il s’agit d’un topic mélangeant des commentaires hors-sujet et des commentaires intéressants mais variés. De plus, il est impossible de tirer un sens à partir de ce nuage de mots.
Étape d'analyse
Sélection du modèle
Après les vérifications de convergence, l'idée est de visualiser toutes les itérations sur un graphique diversité-cohérence. Ce graphique est présenté ci-dessous, et on peut observer qu'il est délicat de l'interpréter directement :

Il est donc préférable de ne tracer que les frontières de Pareto afin de ne garder que les "meilleures" itérations pour chaque modèle, comme ci-dessous :
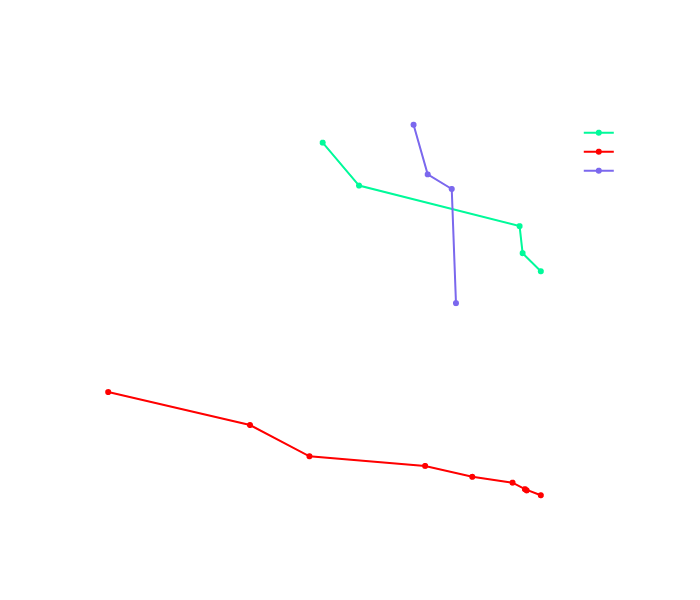
Ce type de graphique est intéressant pour comparer les familles de modèles et sélectionner les itérations intéressantes. Même si nous avons fait moins d'itérations pour NeuralLDA, nous avons décidé de sélectionner l'itération avec une diversité égale à 1. Nous avons également sélectionné le ProdLDA avec la meilleure diversité et le CTM avec la meilleure cohérence : nous avons donc 3 topic models à explorer.
Exploration manuelle des modèles
Tout d'abord, nous utilisons une visualisation PCA afin de voir comment les sujets proposés par tous les modèles sont proches les uns des autres :

Nous pouvons observer que les sujets de NeuralLDA semblent être contenus par les sujets proposés par les deux autres modèles. ProdLDA et CTM, au contraire, proposent tous deux des sujets originaux.
Afin d'explorer plus profondément chaque sujet, il faut comprendre comment chaque modèle définit un "sujet". Comme hérité du LDA, les sujets ont des définitions probabilistes. Chaque thème est défini comme une distribution de probabilité sur le vocabulaire. Cela signifie que, pour un sujet donné, tous les mots du vocabulaire reçoivent un score représentant la force de ce mot dans ce sujet. De même, un document est modélisé comme une distribution de probabilités sur les sujets, ce qui signifie que, pour un document donné, chaque sujet reçoit un score représentant la force de ce sujet dans ce document.
Afin de rendre tous les sujets compréhensibles par les humains, nous avons choisi d'analyser deux représentations synthétiques pour chaque sujet. Tout d'abord, nous avons tracé des nuages de mots. Voir un exemple ci-dessous :

Les nuages de mots sont tracés en fonction de la distribution du sujet sur le vocabulaire (cette distribution étant des scores pour chaque mot), et en ne gardant que les 50 premiers mots. Dans cet exemple, le sujet contient des commentaires qui portent sur le service bancaire proposé dans les bureaux de poste. En effet, les agences postales étudiées proposent également des services bancaires.
La deuxième représentation que nous avons choisie est ce que nous appelons les “documents principaux”. Soit alphat,d le poids du topic t dans la distribution du document d.
Etant donné un sujet t nous calculons un score de document st(d) : comme suit :
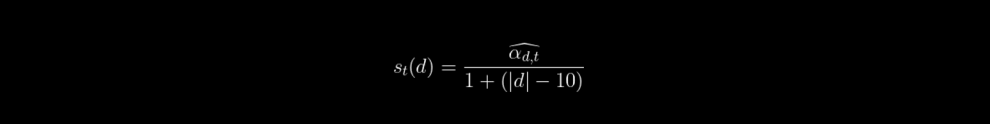
Where âphat,d is the min-max topic-normalized weight of the topic t in the distribution of the document d.
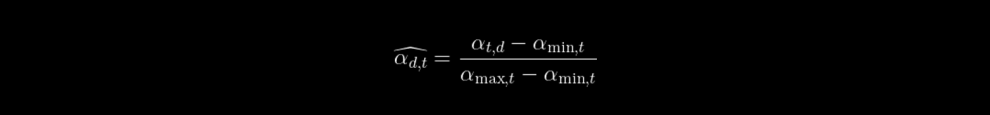
And alphat et alphamax,t respectively the biggest and lowest scores of all documents with respect to a topic t.
Avec alphat et alphamax,t respectivement le score le plus élevé et le plus bas de tous les documents par rapport au thème t.
Le dénominateur du score est une pénalisation sur la longueur du document |d| car nous avons observé que ce score avait tendance à favoriser les longs commentaires.
Une fois tous les documents notés, nous pouvons sélectionner les 5 ou 10 meilleurs documents afin de lire les documents les plus représentatifs. Cette représentation nous permet d'approfondir chaque sujet, en nous permettant de distinguer les sujets les plus proches sur des points précis.
Conclusion
Nous avons vu un processus de bout en bout pour réaliser du topic modeling sur un cas business réel. Ce processus implique principalement des étapes automatiques mais aussi des étapes manuelles pour la sélection du modèle et l'exploration des thèmes.
La sélection manuelle de modèles permet d'ajouter une certaine forme de personnalisation au processus, puisque différents cas pratiques pourraient nous amener à sélectionner des modèles différents. Ainsi, l'étape de sélection manuelle du modèle peut s’avérer nécessaire. Un autre avantage est qu'elle implique davantage l'utilisateur, et augmente la confiance dans le résultat produit.
Inversement, le processus global pourrait être amélioré en rendant automatique l'étape d'exploration des sujets. Cette étape consiste à reformuler tous les sujets sous une forme intelligible pour l'homme. Une exploration plus poussée consisterait à utiliser des modèles de résumé NLP afin de produire quelques phrases fluides décrivant chaque sujet.


