Notre solution SmartDataQuality.ai pour quantifier le problème de qualité des données
Clé de voûte de la performance et facteur clé de nos activités à l'échelle mondiale, les données couvrent sans cesse de nouveaux domaines, s'étendent à de nouvelles applications et représentent un poids croissant.
Il est donc crucial de les comprendre et de disposer d'outils adaptés.
Les données sont quasi-omniprésentes dans le monde actuel et leur volume mondial ne cesse d’augmenter chaque année jusqu’à atteindre les 50 zettaoctets pour l’année 2020 ce qui représente 6 millions de films haute définition d’une durée de 2h. Ce chiffre impressionnant montre l’importance des données de nos jours, surtout pour les entreprises qui souhaitent devenir data-driven et incorporer les données dans leurs prises de décisions. Pour accompagner cette augmentation du volume, la mise en qualité des données est un prérequis indispensable à l’utilisation efficiente des données de l’entreprise, et plus largement à tout projet de Data Science.
À un moment où les entreprises se tournent de plus en plus vers une stratégie ancrée autour des données, Heka.ai propose une série de deux articles : un premier article visera à quantifier de manière pragmatique le problème de la qualité des données sur la base de données de nos partenaires étudiées avec SmartDataQuality.ai, le second préconisera une approche pour adresser la problématique de qualité des données dans l’entreprise.
Quantifier le problème de la qualité des données grâce à notre solution SmartDataQuality.ai
Les projets menés avec nos clients sur leur qualité de données nous ont amenés à imaginer une solution générique permettant d’adresser ce challenge commun à tous les secteurs. C’est la genèse de notre solution : SmartDataQuality.ai. Notre outil permet notamment de :
- Détecter les doublons au sein de vos bases de données, principalement les faux doublons. À titre d’illustration : les bases de données clients sont composées de nombre de doublons difficilement repérables comme “Mathieu Martin” et “Martin Mathieu”. Grâce à la valorisation de méthodologies d’intelligence artificielle, notre solution est capable de repérer ces doublons avec un indice de confiance associé,
- Enrichir les bases de données, avec des informations externes en rapprochant intelligemment différents référentiels. Smart Data Quality est capable d’enrichir les bases de données clients avec des informations socio-démographiques (comme le revenu médian, la répartition des tranches d’âge, …), des informations sur la parcelle cadastrale de l’adresse (comme la surface du terrain, la surface habitable, …). En se donnant la capacité de croiser plusieurs informations, les incohérences apparaissent plus facilement. Plus globalement, l’enrichissement de bases de données constitue un véritable levier pour permettre à l’entreprise d’optimiser ses processus : les communications auprès des clients pourront être plus pertinentes par exemple,
- Réaliser des diagnostics sur la qualité des données en quelques clics. SmartDataQuality.ai permet par exemple de diagnostiquer la qualité des adresses présentes dans une base de données ou la véracité des valeurs numériques.
- Réaliser des traitements de normalisation de données : SmartDataQuality.ai repère les similitudes et propose des normalisations de colonne en se basant uniquement sur l’analyse du fichier de données.
De plus, l’ensemble de ces algorithmes pourront être sauvegardés afin d’analyser leur performance, mais également de les appliquer ultérieurement sur d’autres bases de données.
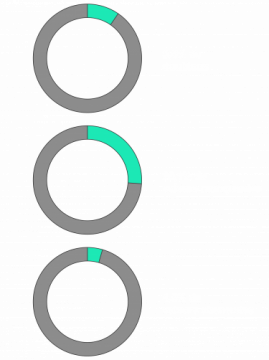
Quelques chiffres concrets autour de la qualité de données :
Ces indicateurs peuvent sembler abstraits, mais ont une réalité opérationnelle forte :
- Près de 10 % des coûts de communications sortantes peuvent être réduits par le traitement de doublons dans les bases de données clients,
- Près d’un quart des activités opérationnelles, comme un entretien téléphonique avec un client ou une intervention de maintenance, peuvent être améliorées en comblant les données manquantes,
- Une bonne qualité de données peut éviter que près de 5 % des factures clients soient envoyées à la mauvaise adresse voire contenir des informations erronées.
De manière générale, cette mauvaise qualité de données s’explique par des erreurs humaines : erreurs de typographies, oublis de saisies de données. Elle peut également être due à une mauvaise communication entre les différentes entités de l’entreprise, voire à des processus métiers perfectibles. Ces erreurs induisent des coûts importants pour les entreprises. Des études ont montré que 1 à 5 % de données erronées entraînent une augmentation des coûts opérationnels de 8 à 12 %. Au-delà des coûts, la mauvaise qualité de données freine la volonté de l’entreprise de devenir data-driven, car elle induit :
- Des décisions risquées voire inadaptées.
- Une inefficacité des activités et processus basés sur les données.
- Très peu de confiance envers les résultats obtenus.
- Des opportunités manquées.
- Une perte de revenus.
Nous verrons dans une publication ultérieure nos préconisations sur comment adresser cette problématique de manière globale dans l’entreprise. Si vous êtes intéressés pour réaliser un diagnostic gratuit d’une de vos bases de données, n’hésitez pas à nous contacter sur l’adresse smartdataquality@sia-partners.com.


