Un cran plus loin avec DocReview, notre solution d’IA d’extraction d’informations dans des documents : traitement des tableaux
DocReview, l’une des solutions d’IA de Sia Partners, permet de lire automatiquement des milliers de documents de tout format (pdf, scan, etc) et d'en extraire les informations clés qu'ils contiennent.
Jusqu’à présent il n’était pas aisé d’extraire les informations contenues dans les tableaux présents dans des documents non structurés.
Et pourtant le besoin se faisait ressentir par nos clients.
C’est désormais possible grâce à la combinaison de plusieurs approches algorithmiques dont nous allons vous parler.
Fort du succès de notre solution d’IA DocReview sur l’analyse de près de 8.000 accords d'entreprise enregistrés par le ministère du Travail entre 2018 et 2021 pour réaliser une étude sur l'essor du télétravail pour “Les Echos”, nous avons voulu enrichir encore les capacités de notre outil.
L’apparition d’un besoin sur Doc Review
Que cela soit dans le domaine de la banque, de l’assurance, de l’immobilier ou toute sorte de secteur, une grande partie de la donnée à utiliser est contenue dans les tableaux présents dans les documents (que cela soit des pdf ou des scan…).
Pour la bonne compréhension de l’article, nous allons illustrer nos propos avec le rapport de Valeur intrinsèque et fonds propres de Solvabilité II d’AXA. Une page type de ce rapport contient un ou plusieurs tableaux et du texte, comme on peut le voir ci-dessous :

Il devient donc essentiel de structurer l’information issue des tableaux et de pouvoir l’extraire afin de capter toute l’information contenue dans les documents non structurés.
Aujourd’hui, avec les avancées technologiques dans le domaine de la computer vision et du natural language processing, obtenir des données provenant de tableaux issues d'images devient possible, et cela de façon non supervisée.
Pipeline pour le traitement des tableaux
Le traitement des tableaux se décompose en quatre grandes étapes : la détection du tableau, la reconnaissance de sa structure, l’extraction du tableau (OCR des cellules identifiées), et enfin l'obtention de réponses à partir de questions posées en langage naturel.
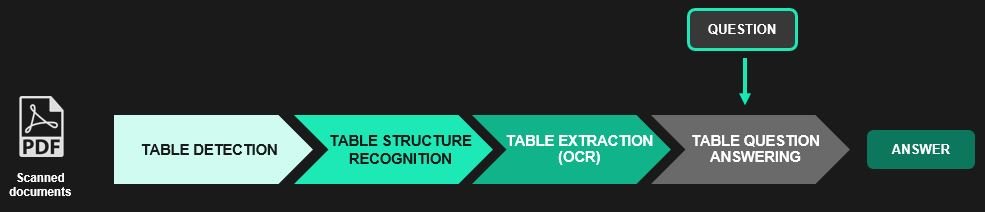
Step 1: Détecter des tableaux dans une image
Pour traiter un document, un pdf (scan ou texte) par exemple, nous le convertissons en un ensemble d’images correspondant à chacune des pages. Bien évidemment, avant de procéder à la détection, il conviendra de réaliser une étape de preprocessing afin de préparer l’image et d’obtenir de meilleurs résultats lors de la détection.
La détection de tableaux consiste à identifier les zones où se situent les tableaux au sein d’une image. Les récents progrès en computer vision, combinés avec des datasets de plus en plus importants, permettent d’obtenir des résultats satisfaisants.
Il existe plusieurs packages open-source sur Python permettant de faire de la détection de tableaux comme Camelot, tabula, pdf plumber etc. Dans la plupart des cas, le plus performant reste Camelot qui réalise également l’extraction des tableaux.
Camelot a deux méthodes pour réaliser l’extraction : ”Lattice” et “Stream”. “Lattice” est utilisé pour analyser les tableaux qui ont des lignes délimitées entre les cellules, tandis que “Stream” est utilisé pour analyser les tableaux qui ont des espaces vides entre les cellules pour simuler une structure de tableau. Mais c’est à l’utilisateur de sélectionner la méthode à mettre en place; c'est à dire qu' il n’y a pas de classification automatique dans Camelot. Par ailleurs, ces packages sont incapables de traiter les pdf scans. Il faut donc trouver des solutions plus générales.
La plupart des méthodes de détection de tableaux dans des images aujourd’hui se basent sur l'apprentissage profonf ou deep learning en ajustant un modèle pré-entraîné de détection d'objets comme Faster RCNN, Cascade R-CNN ou Cascade mask R-CNN, sur des datasets créés pour cette tâche (cTDaR, Marmot, …).
Il est donc possible de détecter des tableaux. Néanmoins, il existe une grande variété de tableaux qui ne pourront pas être traités de la même manière dans l’étape de reconnaissance de structure. Il convient donc de les classifier.
Step 2: Détecter et classifier des tableaux dans une image
D’autres méthodes, en plus de la détection, sont capables de classifier les tableaux en plusieurs types. C’est notamment le cas avec CascadeTabNet qui est capable de détecter et classifier deux types de tableaux : “bordered” et “borderless”. Un “bordered” (c) est un tableau pour lequel un algorithme peut utiliser uniquement les positions des lignes pour estimer les cellules et la structure globale du tableau. Un “borderless” (a) est un tableau qui n'a pas de lignes. Il y a également les “partially bordered” (b), à mi-chemin entre les deux premiers types.
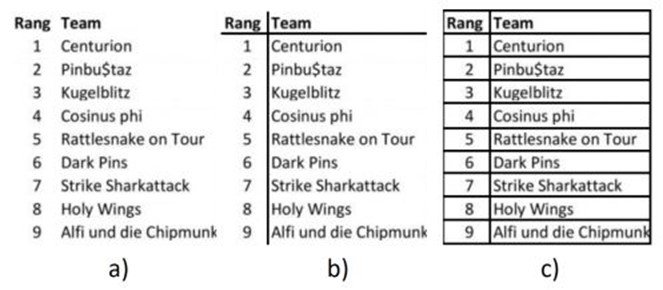
Sur la page que l’on avait sélectionnée, le tableau trouvé se trouve ci-dessous et a été classifié comme borderless.

Step 3: Reconnaître la structure d’un tableau
La reconnaissance de la structure d’un tableau consiste à identifier ses lignes, ses colonnes, et ses cellules ainsi que leurs coordonnées.
Il existe plusieurs approches pour répondre à ce défi complexe : les approches heuristiques basées sur des règles pour reconnaître ou analyser les structures des tableaux à partir des signaux visuels (Multi-type-TD-TSR), les approches basées sur l'apprentissage profond (DeepDeSRT, etc), d’autres basées sur des réseaux de convolution de graphes (GraphTSR, etc).
L’approche présentée dans Multi-type-TD-TSR, s’inspirant du travail fait dans CascadeTabNet, se base sur une combinaison de règles sur l’image d’un tableau. Elle traite différemment les différents types de tableaux : bordered, borderless, et partially bordered.
Deux principales opérations sont utilisées pour déterminer la structure des tableaux : la dilatation et l’érosion. A l'inverse de la dilatation, l'érosion entraîne les zones claires de l'image à s'amincir tandis que les zones sombres s'agrandissent. L’érosion est utilisée sur les bordered pour détecter les lignes verticales et horizontales, qui doivent être conservées, tout en supprimant les caractères des cellules du tableau. La dilatation, quant à elle, est appliquée successivement pour restaurer la structure du tableau d'origine, puisque l'érosion raccourcit les lignes. De plus, l'érosion est appliquée sur les tableaux borderless pour ajouter les lignes manquantes, et donc reconstruire explicitement le tableau .

Une fois que la structure sera bien identifiée, il faut déterminer ce qui est écrit dans chacune des cellules du tableau, c’est là que l’OCR (reconnaissance optique de caractères) rentre en piste. A la fin de cette opération, nous obtiendrons notre tableau xlsx.*

Step 4: Répondre à des questions en langage naturel
Une fois notre tableau transformé sous format excel, il faut parvenir à extraire de l’information en fonction d’une requête ou une question en langage naturel.
Le modèle TAble PArSing (TAPAS) créé par Google est le plus utilisé pour répondre à des questions sur des tableaux. En quelques mots, TaPas s'entraîne à partir d'une supervision faible, et prédit la réponse finale en sélectionnant des cellules de tableaux et en appliquant éventuellement un opérateur d'agrégation correspondant à cette sélection. TaPas étend l'architecture de BERT pour coder les tableaux en entrée, et s'initialise à partir d'un pré-entraînement conjoint de passages de texte et de tableaux extraits de Wikipedia.
Haystack offre une implémentation de ce modèle à l’aide d’une fonction appelée TableReader. Il est donc possible de construire un pipeline, utilisant TAPAS, prenant en entrée un tableau xlsx et une question, pour avoir en output une réponse.
On peut poser des questions simples ne nécessitant que la sélection d’une seule cellule. Par exemple : “What is the Group Solvency 2 ratio in 2021 ?”, ou “What was the Group EOF in 2020 ?”.
TaPas prédit la réponse finale en sélectionnant des cellules de tableaux et en appliquant éventuellement un opérateur d'agrégation (sum, count, average, ou none) correspondant à cette sélection, comme expliqué précédemment. Il est donc possible de poser des questions plus complexes comme “What is the average Group Solvency 2 ratio during 2020-2021 ?”.
Certains documents contiennent plusieurs tableaux, comme c’est le cas sur le rapport illustrant notre exemple. On adoptera donc une démarche en 2 temps :
- Identifier un sous-ensemble de tableaux pour lesquels on a de bonnes chances d’obtenir la réponse voulue
- Poser la question sur cet ensemble restreint, et conserver la meilleure réponse.
La pipeline en une image
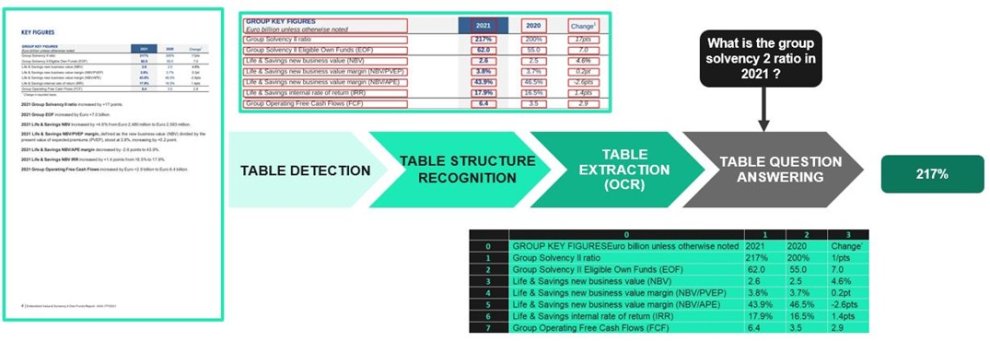
L’intégration du traitement des tableaux au sein de Doc Review
Le pipeline présenté auparavant ne permet d'extraire que des informations issues de tableaux dans des images, mais ce qui nous intéresse vraiment c'est d'arriver à extraire l’information présente dans le document tout entier, texte et tableaux confondus.
Lorsque l’on cherche à répondre à une question dans un texte, on récupère d'abord des passages candidats, puis on en extrait la bonne réponse. Il faut, ainsi, adopter une approche similaire avec les tableaux et le texte. Dans ce contexte, Deepset a proposé une solution en codant conjointement les textes, les tableaux et les questions dans un espace vectoriel unique.
Haystack propose une implémentation de ce cas à travers le TableTextRetriever, que l’on peut insérer dans un pipeline pour d’abord extraire les passages et tableaux candidats puis la réponse finale parmi eux. On peut ainsi prendre en entrée de notre pipeline une question en langage naturel, le texte issu de l’OCR, les tableaux trouvés en xlsx, et obtenir en sortie la réponse souhaitée indépendamment de son emplacement dans le document (tableau, passage du texte, etc.)
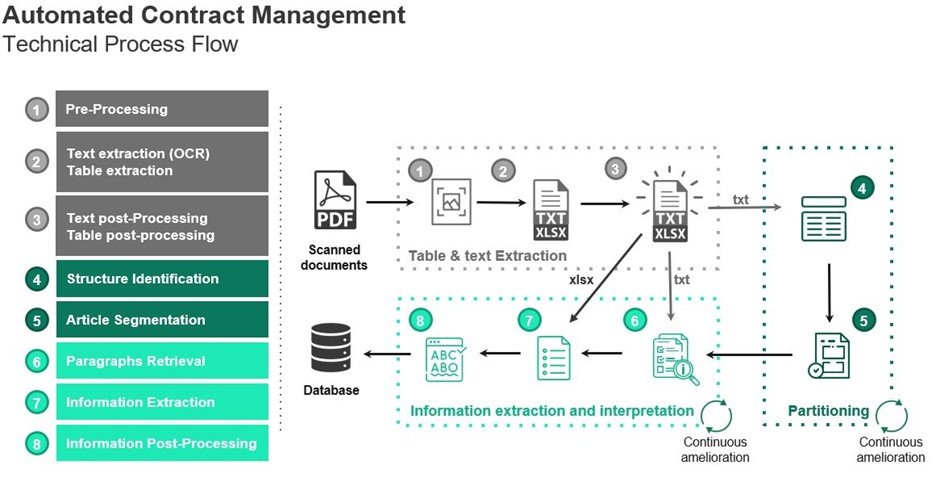
Conclusion
Nous sommes maintenant capables d’extraire les informations d’un document comportant du texte et des tableaux et également de répondre aux questions posées par un utilisateur, suivant une approche non supervisée.
Doc Review est une intelligence artificielle complexe capable d'extraire des informations clés issues de documents. Plusieurs approches s'apparentant à la Computer Vision et au Traitement Automatique du Langage (TAL) ont dû être utilisées de façon combinée afin d'atteindre nos objectifs. L'association de l'apprentissage automatique supervisé et non supervisé permet à l'utilisateur d'obtenir d'excellents résultats sans fournir de base de données, puis d'améliorer la précision et la spécificité de l'algorithme en utilisant l'approche supervisée.
Si vous souhaitez en savoir plus sur notre solution, n'hésitez pas à nous contacter.


