Une IA pour automatiser l’analyse réglementaire
Analyse de textes réglementaires grâce à une méthode de Pattern Recognition en Python
Introduction
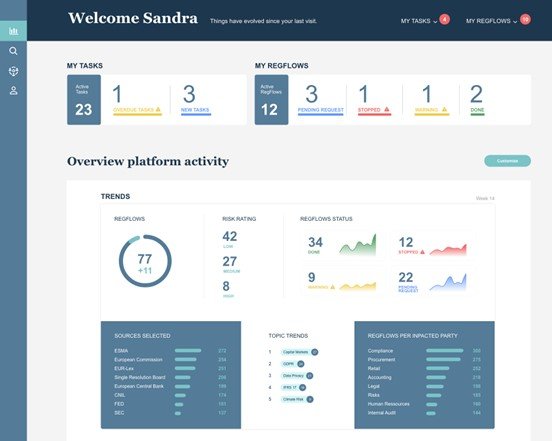
Chaque jour de nombreux articles de régulation apparaissent et sont analysés par des équipes de compliance. Cette veille réglementaire est devenue une nécessité pour les acteurs du secteur de la banque ou de l’énergie. C’est pourquoi Heka a développé le produit RegReview (Figure 1) qui traite ces multiples sources en collectant les articles (pour aller plus loin sur la collecte de données , vous pourrez trouver un post à propos du scraping effectué par RegReview) , en les analysant et en accélérant leur diffusion aux parties prenantes.
Dans cet article nous présentons une de nos méthodes pour analyser les textes réglementaires.
L’utilisation d’algorithmes de traitement de texte permet d’analyser de grands volumes de documents pour en extraire les caractéristiques principales (thèmes, langage, synthèse) et faciliter le travail des équipes effectuant la veille. Le type d’analyse auquel nous allons nous intéresser ici est la Pattern Recognition, un des blocs d’analyse effectuée par RegReview qui consiste à rechercher des termes prédéfinis (ici appelés topics) dans un texte. Pour ce faire, il va d’abord falloir définir les termes que l’on va rechercher dans les textes.
Elaboration d’une Taxonomie
L’analyse réglementaire et juridique est une discipline très spécifique (par les termes utilisés, les acronymes, etc… ) et changeante (de nouvelles réglementations et sujets apparaissent régulièrement). Les algorithmes de NLP ne répondant pas exactement au besoin des analystes utilisant RegReview, nous avons décidé de construire une IA hautement paramétrable par les experts utilisateurs de RegReview qui repose essentiellement sur la définition d’une taxonomie. C'est-à-dire un dictionnaire de topics à rechercher en pratique constituée de plusieurs centaines de lignes.
La taxonomie permet d’identifier et de hiérarchiser les topics à rechercher pour ensuite catégoriser intelligemment les articles. Par définition une taxonomie est une classification, un vocabulaire hiérarchisé ou d’après le Larousse une "suite d’éléments formant des listes qui concernent un domaine" dans notre cas.
Nous en avons donc construit une adaptée à notre besoin. Ci-dessous un extrait de la taxonomie qui a été construite pour l’analyse d’articles de régulation bancaire.
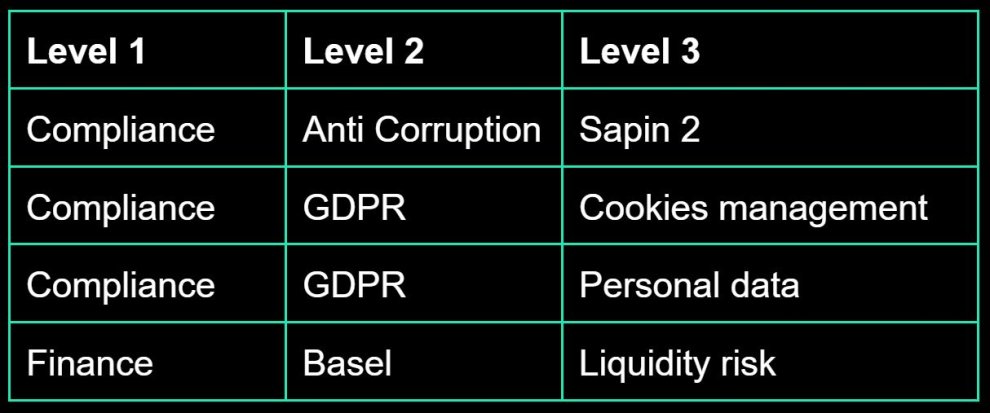
Cette taxonomie a été construite en 3 niveaux de topics (et lorsque nécessaire, nous avons ajouté des synonymes aux topics par soucis de complétude). Par exemple dans le topic de niveau 1 assez large “Compliance”, nous avons le topic de niveau 2 “Anti Corruption” qui lui même contient le topic précis de niveau 3 “Sapin 2” étant directement le nom d’une loi (et ce topic de niveau 3 a pour synonyme “Sapin II”)
Recherche de topics grâce au PhraseMatcher de Spacy
Une fois la taxonomie définie, nous pouvons passer à l’analyse avec Pattern Recognition. Pour cela nous utilisons le modèle PhraseMatcher de Spacy qui permet de faciliter la recherche de termes spécifiques puisqu’il peut rechercher plusieurs topics à la fois. Il s’avère très efficace sur de grandes listes de topics et peut également gérer certains cas particuliers comme les formes plurielles par exemple.
Le PhraseMatcher s’emploie de la manière suivante, il faut donc charger un modèle de Spacy puis instancier le matcher :

Ensuite, nous pouvons chercher un topic donné dans le texte comme expliqué ci-dessous :

Dans notre cas, une recherche des topics de niveau 2 et 3 (et de leurs synonymes) est effectuée pour tous les articles collectés et l’occurrence de chaque topic dans un article donné est conservée.²
Enfin, les topics rattachés au topics trouvés sont aussi associés à l’article (les topics dits “rattachés” sont les topics de niveau supérieur auxquels un topic est lié, “Compliance” est rattaché à “Anti Corruption” dans l’extrait fourni par exemple). Ces topics rattachés vont permettre de placer les articles dans des catégories plus larges.
Traitement des topics et Visualisation
Les topics trouvés pouvant être nombreux, il est nécessaire qu’ils soient traités après analyse pour faciliter la compréhension à l’utilisateur. Les topics trouvés sont donc priorisés puis filtrés. La priorisation est un fin équilibre pour choisir ceux qui sont les plus pertinents et différenciants, et éliminer ceux qui sont trop communs ou redondants. Un score est ainsi déterminé en fonction de ces critères et nous permet de trier les topics.
Conclusion
Pour conclure, cette méthode d’analyse de texte a pour avantage d’être simple et donc rapide à mettre en place. Elle peut servir de première version, d’analyse de base dans un outil comme RegReview mais aura besoin d’être complétée par d’autres blocs pour constituer une méthode d’analyse générale et précise.
C’est pourquoi dans l’analyse faite pour le produit RegReview, d’autres méthodes et algorithmes de NLP viennent compléter la méthode de Pattern Recognition présentée dans cet article. Par exemple, la méthode de zero-shot qui est présentée au sein d’un autre article d’Heka à propos de l’automatisation de veille industrielle grâce à des méthodes de NLP : Article à propos de la veille industrielle.


