AI to automate regulatory analysis
Analysis of regulatory texts using a Pattern Recognition method in Python
Introduction
Every day, numerous regulatory articles appear and are analyzed by compliance teams. This regulatory monitoring has become a necessity for stakeholders in the banking or energy sector. This is why Heka has developed the RegReview product (Figure 1) which processes these multiple sources by collecting the articles (To go further on data collection, you can find a post about the scraping done by RegReview) , analyzing them and then accelerating their distribution to the aforementioned stakeholders.
In this article we present one of our methods to analyze regulatory contents.
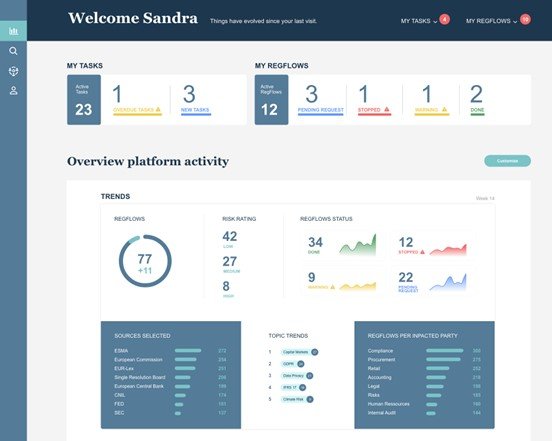
The use of text processing algorithms allows the analysis of large volumes of documents in order to extract the main characteristics (topics, language, synthesis) and to facilitate the work of the teams performing the monitoring. The type of analysis we will focus on here is Pattern Recognition. One of the analysis blocks performed by RegReview which consists in searching for predefined terms (here called topics) in a text. To do this, we first have to define the terms we are going to search in the texts.
Elaboration of a Taxonomy
Regulatory and legal analysis is a discipline that is very specific (by the terms used, the acronyms, etc.) and changing (new regulations and topics appear regularly). NLP algorithms do not exactly meet the needs of analysts using RegReview, so we decided to build an AI that is highly customizable by RegReview's expert users and is essentially based on the definition of a taxonomy. That is to say, a dictionary of topics to be searched, in practice consisting of several hundred lines.
Taxonomy allows to identify and prioritize the topics to be searched and then to smartly categorize the articles. By definition, a taxonomy is a classification, a hierarchical vocabulary or, according to the Cambridge Dictionary ,"a system for naming and organizing things into groups that share similar qualities" in our case.
We have therefore built a taxonomy adapted to our needs. Below is a sample of the one that was built for the analysis of banking regulation articles.
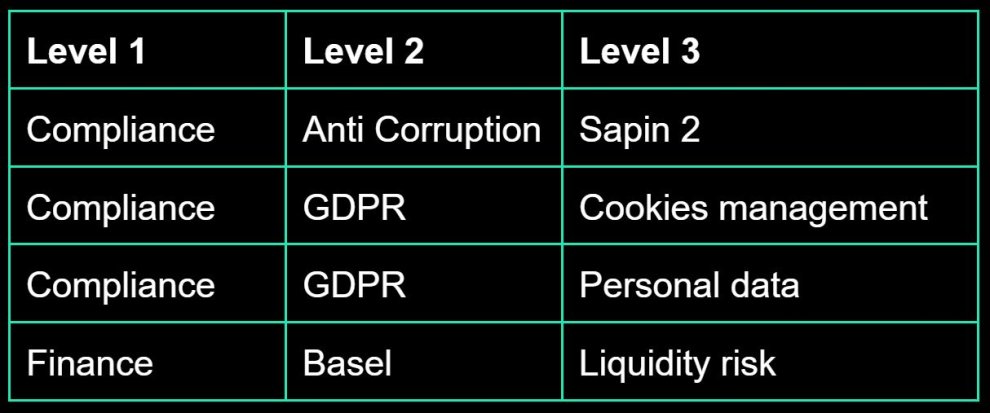
This taxonomy has been built in 3 levels of topics (and when necessary, we have added synonyms to the topics for completeness). For example in the broad level 1 topic "Compliance", we have the level 2 topic "Anti Corruption" which itself contains the specific level 3 topic "Sapin 2" being directly the name of a law (and this level 3 topic has as synonym "Sapin II").
Search for topics with Spacy's PhraseMatcher
Once the taxonomy is defined, we can move to the analysis with Pattern Recognition. For that we use the PhraseMatcher model of Spacy which allows the search of specific terms since it can search several topics at the same time. It is very efficient on large lists of topics and can also handle some special cases like plural forms for example.
The PhraseMatcher is used in the following way, so you have to load a Spacy template and then instantiate the matcher:

Then we can search for a given topic in the text as explained below:

In our case, a search for level 2 and 3 topics (and their synonyms) is performed for all collected articles and the occurrence of each topic in a given article is kept.
Finally, the topics attached to the found topics are also associated to the article (the so-called "attached topics" are the higher level topics to which a topic is linked, "Compliance" is attached to "Anti Corruption" in the provided excerpt for example). These linked topics will allow you to place the articles in broader categories.
Data processing and visualization
As the topics found can be numerous, it is necessary that they be processed after analysis to facilitate the user's understanding. The topics found are therefore prioritized and filtered. The prioritization is a fine balance to choose those that are the most relevant and differentiating, and eliminate those that are too common or redundant. A score is then determined according to these criteria and allows us to sort the topics.
Conclusion
To conclude, this text analysis method has the advantage of being simple and therefore quick to implement. It can be used as a first version, as a basic analysis in a tool like RegReview but will need to be completed by other blocks to constitute a general and precise analysis method.
This is why in the analysis made for the RegReview product, other NLP methods and algorithms are added to the Pattern Recognition method presented in this article. For example, the zero-shot method which is presented in another article of Heka about the automation of industrial intelligence thanks to NLP methods : Industrial watch article.

