Visualisation et clustering des données de parcours d'achat
L'analyse des données de parcours clients, en particulier celles de parcours d'achat, est une étape essentielle en data marketing afin de mieux comprendre comment les clients perçoivent et interagissent avec différents produits et services d'une marque.
L'exploration de ces parcours permet ainsi d'obtenir des informations granulaires mais aussi d'optimiser et d'améliorer l'expérience des futurs clients, par exemple en recommandant à certains d’entre eux des articles achetés dans des parcours similaires.
Cette analyse des parcours d'achat des clients a plusieurs objectifs :
- Construire une vision globale et synthétique de tous les parcours clients
- Identifier les principaux groupes de parcours clients similaires
- Identifier les chemins vertueux (ou les produits clés) qui génèrent de la valeur et de la fidélité
- Inversement, identifier les chemins négatifs qui conduisent à des pertes de clients
- Identifier les intéractions entre produits qui génèrent de la synergie
Cependant, compte tenu de la taille et de la complexité croissantes des données de parcours client, atteindre ces objectifs n'est pas une tâche aisée. Il est ainsi parfois difficile d'extraire des informations pertinentes de parcours très fragmentés. Pour donner un ordre d’idée, une marque qui proposerait 100 produits différents à l'achat (ce qui est relativement faible) et qui souhaiterait analyser des parcours clients de 10 achats (ce qui est également assez faible) ferait donc face à un nombre possible de parcours clients différents de l'ordre de 1019 (et cela sans même prendre en compte les possibilités d'achat de plusieurs produits en même temps à chaque étape).
De fait, les méthodes standards d'analyse (comme le journey mapping) se retrouvent souvent dépassées et ne permettent pas d’exploiter toute la richesse des données de parcours client. L'utilisation de techniques plus avancées issues du machine learning et du deep learning est donc devenue nécessaire.
Dans cet article, nous allons décrire deux méthodologies différentes qui permettent de tirer profit des données de parcours d’achat :
- L’utilisation d’algorithmes de Process Mining afin de construire une vision synthétique des données et d’en extraire les informations utiles pour faciliter la prise de décision
- Une méthodologie de clustering fondée sur l’utilisation des autoencoder neural networks
1) Visualisation des données de parcours d’achat à partir du Process Mining
Lors de l'analyse de parcours clients, la première étape consiste comme souvent à essayer de visualiser les données. Cependant, étant donné la taille et la complexité des données en question, construire une visualisation exhaustive de tous les parcours aboutit souvent à des représentations complexes et illisibles. Par exemple, en utilisant les méthodes de visualisation classiques comme les directed-graphs et le Sankey Diagrams avec des données de parcours d’achat que nous avons générés artificiellement, nous aboutissons à des graphiques presque inexploitables :
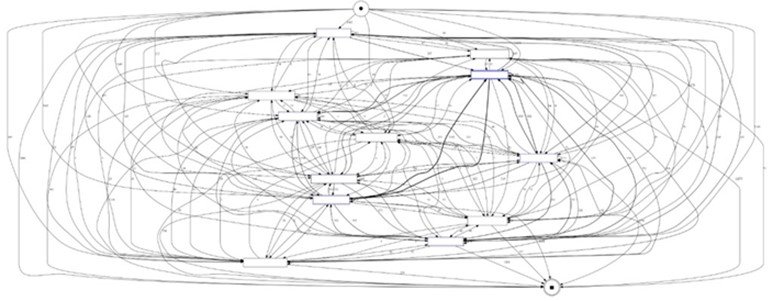
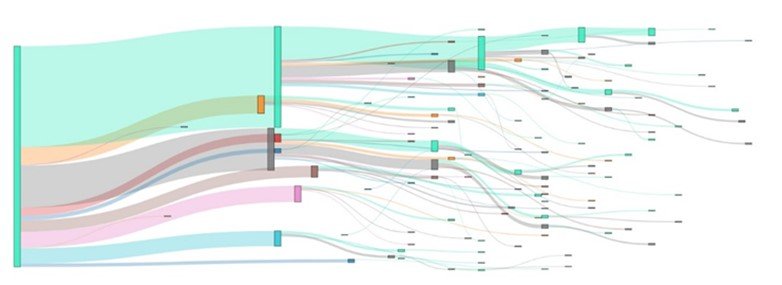
Il existe cependant un ensemble d'algorithmes spécialement conçus pour construire des représentations graphiques de données de processus complexes (c'est-à-dire de données de série d'événements) et en extraire des informations : Le Process Mining. Il s'agit d'un ensemble de méthodes qui permettent de construire une vision globale et synthétique et d'extraire des informations utiles de données de processus afin de faciliter la prise de décision.
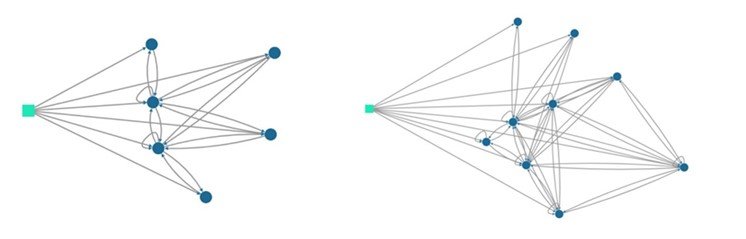
L'un des principaux algorithmes de Process Mining est l’Heuristic Miner. Il s'agit d'un algorithme qui utilise une approche statistique afin d’extraire les relations de dépendance entre les actions prises au fil du temps. Ainsi, avec les mêmes données artificielles que précédemment, l’algorithme permet de construire de nouvelles représentations en jouant avec ses différents paramètres :
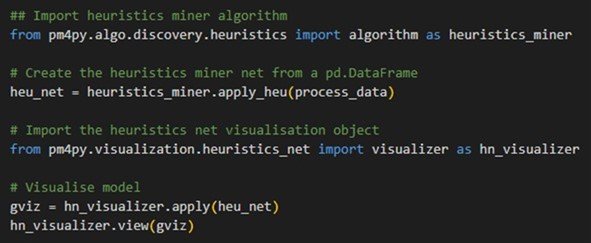
Il existe une librairy Python très pratique permettant d'utiliser les principaux algorithmes de Process Mining : pm4py. Dans le cas du Heuristic Miner, l'algorithme peut être appliqué très rapidement à un jeu de données en quelques lignes de code :
Dans le cas des données de parcours d’achat, ces visualisations sont très utiles afin de construire une vision globale des parcours client et d’identifier les produits critiques, les chemins vertueux, les principales dépendances et synergies entre différents produits, le cross-sell entre des groupes de produits etc.
Par exemple, avec des données de parcours d'achat dans lesquelles nous ne tenons pas compte de l'ordre des achats (chaque produit est donc associé à un seul nœud du graphe, contrairement au Sankey Diagrams), l'utilisation du Heuristic Miner (paramétré à un certain degré de simplification) peut permettre d'identifier les produits “bridge”.
2) Clustering des données de parcours d’achat
Le clustering des données de parcours client est une approche utilisant des algorithmes qui analysent les parcours afin d’identifier des groupes de consommateurs ayant des comportements d'achat similaires. Ces clusters permettent notamment d’optimiser, d'améliorer et de personnaliser l'expérience client.
La méthodologie présentée dans cet article s’inspire des méthodologies de clustering d'images qui représentent chaque image par une matrice de pixels enregistrés comme des valeurs d'intensité de couleurs spécifiques (par exemple des nuances de gris). Cette approche comporte trois étapes :
- Représentation de chaque parcours client par une “matrice d’action”
- Réduction de dimension des données de parcours clients avec un autoencoder neural networks
- Clustering et calcul des centroïdes (parcours moyens) de chaque cluster
Représentation de chaque parcours par une “matrice d’action”
Pour regrouper les parcours d'achat similaires, il est nécessaire de prendre en compte les produits achetés par chaque consommateur, l'ordre dans lequel ces produits ont été achetés et éventuellement différentes autres valeurs (par exemple, le nombre de produits achetés ou le temps écoulé depuis le dernier achat). Pour cela, chaque parcours d'achat est représenté par une "image" ou une "matrice d'action" :

Réduction de dimension des données de parcours clients avec un autoencoder neural networks
La base de données obtenue à l'étape précédente est très volumineuse et dispersée (“sparse”). L'utilisation d’un algorithme de réduction de dimension permet de conserver les informations les plus pertinentes pour le futur clustering. Dans cette méthodologie, les “matrices d’action” sont traitées à partir d’un autoencoder neural networks. La bibliothèque Python Keras fournit les outils nécessaires à la mise en place du modèle. L’algorithme de l’ACP (analyse en composantes principales) peut également être utilisé.
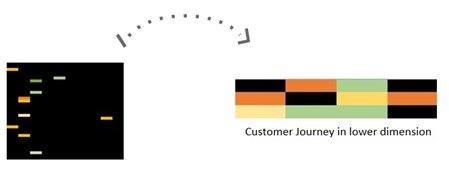
Clustering et calcul des centroïdes (parcours moyens) de chaque cluster
Enfin, à partir des “matrices d’action” de faible dimension obtenues précédemment, un algorithme de clustering est utilisé - par exemple les algorithmes DBSCAN ou HDBSCAN de la bibliothèque scikit-learn - afin de créer des groupes de parcours d'achat similaires. Le parcours d'achat moyen (centroïde) de chaque cluster est ensuite calculé et reconstitué en grande dimension.
Chaque cluster est ainsi représenté par un unique parcours client nous permettant d’identifier les principales tendances des parcours d’achat lui appartenant.
Conclusion: feedback
Afin de conclure la présentation de ces deux méthodologies, nous les avons implémentées à partir d’une base de données réelle de parcours d'achat. Le nombre de parcours était de l’ordre de 50 000, le nombre d'achats dans chaque parcours était compris entre 1 et 10 (avec une forte majorité de parcours à achat unique : 90%), et le nombre de produits différents était de 172.
L'utilisation du process mining s'est avérée très efficace et nous a permis d'obtenir des résultats facilement exploitables. En effet, compte tenu du volume de données, il était difficile de visualiser l'ensemble des parcours d'achat à l'aide de méthodes traditionnelles telles que les directed-graphs ou les Sankey Diagrams. Au contraire, le process mining nous a permis d'obtenir une visualisation synthétique (en paramétrant l'algorithme en fonction du niveau de détail souhaité) et d'identifier les principaux liens et synergies entre chaque produit.
La méthodologie de clustering a donné des résultats moins pertinents. Ainsi, une partie très faible des données a été regroupée au sein des clusters, tandis que la majorité a été considérée comme du bruit. De plus, les clusters n'ont permis d’identifier que les groupes de parcours clients ayant acheté en premier les mêmes produits ou encore les groupes de parcours clients dans lesquels les mêmes produits ont été achetés plusieurs fois de suite. La principale raison de ce résultat décevant est le faible nombre de parcours clients avec plus d'un achat (10% et 3% seulement pour les parcours avec plus de deux achats) et le grand nombre de produits pouvant être achetés à chaque étape du parcours (172). L’algorithme a de fait besoin de plus de long parcours clients afin de mieux les distinguer et les regrouper. Les résultats obtenus pourraient ainsi se révéler bien meilleurs et plus exploitables avec des données plus étendues, plus riches, et avec des parcours clients et des chemins de rétention plus complexes.


