Transformez votre base de documents en données structurées exploitables
Avec Doc Review, chargez vos documents, posez des questions et obtenez des réponses.
Introduction
Dans un monde de plus en plus numérique, il a été démontré que 80 % des informations des entreprises restent dans des documents non structurés tels des contrats, des factures, des bons de commande ou des notes. Le traitement de ces documents se fait souvent manuellement. Cela prend du temps, coûte cher et est sujet à l'erreur humaine.
Doc Review est une solution basée sur l'IA permettant de lire automatiquement des milliers de documents et d'en extraire les informations clés. Cette capacité à traiter de grandes quantités de documents sur une variété de sujets différents aide nos clients à résoudre ce problème. Par exemple, en analysant automatiquement plus de 8000 conventions collectives, Doc Review a aidé un grand journal français à réaliser une étude sur l'essor du travail à distance en France. Nous avons également aidé une compagnie d'assurance à ajouter des milliers de vieux contrats papier dans leur tout nouvel outil CRM.
Avancée majeure dans le domaine du traitement du langage naturel
Heka, l'écosystème de solutions d'Intelligence Artificielle développé par Sia Partners, a souvent été contacté pour ce type de mission. Jusqu'à récemment, il était difficile de réaliser un outil capable de répondre à ces différents cas d'usage :
- Les documents sont de toutes formes et de toutes tailles
- Les informations à extraire dépendent du client et de son domaine.
- La diversité des informations recherchées rend impossible l'existence d'un modèle unique.
Aujourd'hui, les progrès fulgurants dans le domaine de l'intelligence artificielle et notamment dans le domaine du traitement du langage naturel avec des modèles tels que BERT ( Pré-entraînement de transformateurs profonds bidirectionnels pour la compréhension du langage) ou l'essor du Question Answering nous permettent désormais de relever ce défi. Quel que soit le type de document ou son format, qu'il s'agisse d'un document mal scanné (image d'un pdf) ou d'une information de valeur, ce sont les cas d'usages typiques auxquels nous avons tenté de répondre.
Structure générale de Doc Review
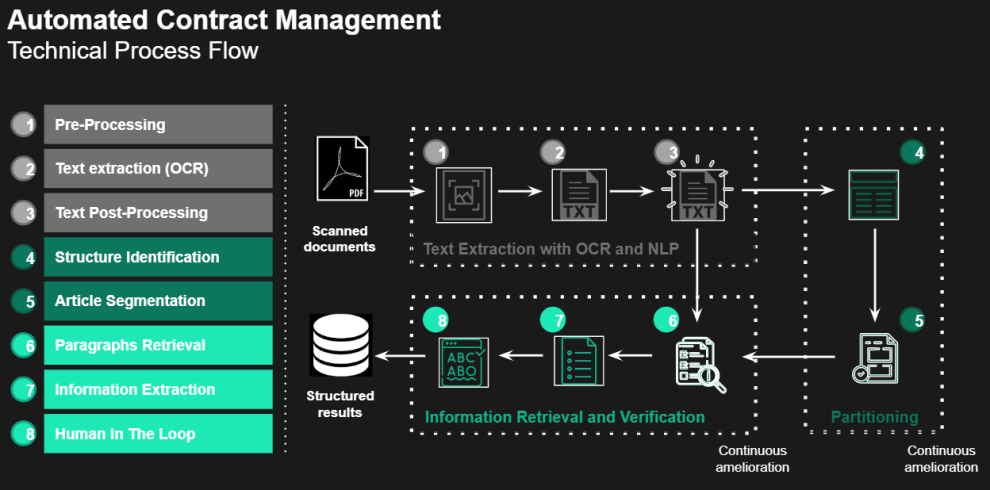
Dans les sections suivantes, nous présenterons les huit différentes étapes que nous avons développées pour atteindre notre objectif - extraire des informations écrites en langage naturel dans un document non structuré .
Pour illustrer cela, nous prendrons l'exemple d'un contrat comme celui-ci (convention collective). Le datapoint - l'élément clé que nous cherchons dans le document - que nous allons extraire sera la governing law de ce contrat (section 6.4 Governing Law).
Pour réaliser ce processus, les entrées nécessaires sont le document numérisé et une question. Le document est un contrat de 56 pages et la question est une simple question posée en langage naturel comme si nous nous adressions à un être humain : Sous quelles lois cet accord sera-t-il régi?
Doc Review lit et transcrit automatiquement grâce à notre OCR développé en interne (étape 1-2-3)
La première étape pour lire un document est d'effectuer une reconnaissance optique de caractères (Optical Character Regnition). L'OCR consiste à extraire le texte d'une image. La qualité de l'extraction va évidemment dépendre de la qualité de l'image. Il nous appartient donc de prétraiter l'image afin que l'OCR se déroule dans les meilleures conditions.
Différentes étapes doivent être prises en compte :
- Détection et correction de l'asymétrie
- Automatisation du traitement des couleurs pour les documents qui ne sont pas en noir et blanc
- Binarisation pour éliminer les flous et le bruit
- Correction de l'arrière-plan irrégulier (ex: filigranes, tâches)
- Détection et extraction des objets tables

Extraire le texte de l'image est la première étape, mais conserver la structure du document est encore plus utile.
Doc Review conserve la structure du document - (étape 4-5)
L'objectif ici est de garder une trace de la structure du document. Identifier les titres, les sous-titres, quel paragraphe appartient à quelle section peut être utile non seulement à l'utilisateur pour naviguer dans le document, mais aussi pour extraire des datapoints. Si Doc Review peut identifier un titre d'article tel que "Governing Law", il y a de fortes chances que la valeur du datapoint que nous recherchons se trouve dans ce paragraphe.
Pour garder la trace de la structure, nous devons éliminer le bruit dans le document. La première étape consiste à identifier le type de page; s'il s'agit par exemple d'une page de couverture, d'une table des matières ou d'une page de contrat. Ensuite, nous devons distinguer l'en-tête/le pied de page du texte de même que le numéro de page.
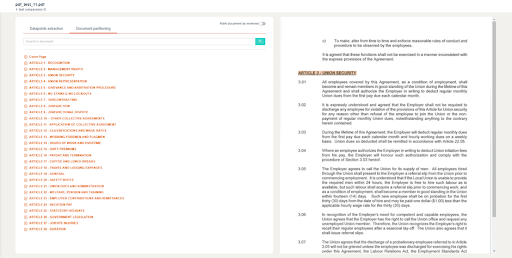
Le résultat est une transcription parfaitement lisible et ordonnée du document que nous avons appelé "Partitionnement du document". Les utilisateurs peuvent bénéficier de cette fonctionnalité à travers l'interface utilisateur. Comme vous pouvez le voir ci dessous sur la figure 3, la partie droite représente le pdf original, la partie gauche représente la segmentation faite par Doc Review.
Doc Review extrait les informations clés grâce au NLP (étapes 6-7)
Comme tout problème d'apprentissage automatique, la première étape avant la modélisation est d'identifier le type de défi : apprentissage supervisé ou non supervisé ?
L'extraction de la governing law dans un contrat que nous n'avons jamais vu auparavant est un apprentissage non supervisé, ce qui nous laisse avec la question suivante : comment extraire un datapoint d'un document inconnu sans aucun exemple labellisé?
L'algorithme va procéder comme le ferait un analyste. Premièrement, il jette un coup d'œil au document et récupère les paragraphes où la réponse pourrait se trouver. Ensuite, il lit attentivement les paragraphes récupérés pour en extraire la réponse. En termes de NLP, la première étape est appelée recherche de paragraphes ou paragraph retrieval et la deuxième étape, question answering.
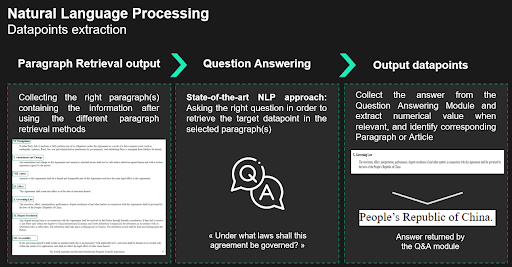
Recherche de paragraphes à l'aide du partitionnement du document
La première approche pour récupérer les paragraphes candidats serait d'exploiter le partitionnement du document. On peut imaginer le document comme un dictionnaire dont la clé serait le nom de l'article, et la valeur le paragraphe associé. Lorsque des mots-clés ou des noms d'articles sont fournis, nous pouvons faire correspondre ces entrées avec les noms d'articles pour établir une liste de paragraphes candidats. Ensuite, nous exécutons le module de question answering sur le paragraphe identifié.

Recherche de paragraphes à l'aide de la recherche de passages denses
L'approche précédente, lorsqu'on lui fournit des noms d'articles ou des mots-clés fonctionne. Mais qu'en est-il si l'utilisateur n'a aucune idée de ces entrées ?
C'est là que le DPR1 (Dense Passage Retrieval) entre en jeu. Le DPR se compose de deux parties : un récupérateur (retriever) et un lecteur (reader). L'algorithme DPR prend en entrée une requête - une question en langage naturel sur la clause que nous voulons retrouver, par exemple Sous quelles lois cet accord sera-t-il régi ? - et un texte brut, sortie de l'OCR.
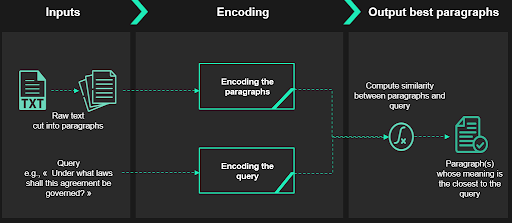
Le récupérateur va diviser le texte fourni en paragraphes. Ensuite, il encode ces paragraphes et la requête (avec le même encoding). Il mesurera ensuite la similarité cosinus d'un paragraphe et de la requête et les classera, du plus proche au plus loin.
Le lecteur - qui peut être assimilé à un module de question answering - passera ensuite en revue les paragraphes les plus proches (en termes de similarité cosinus) renvoyés par le récupérateur pour en extraire la réponse finale.
Classement
Enfin, nous avons différentes réponses provenant de différentes méthodes. La dernière étape consiste à trouver un moyen de classer ces réponses afin de n'en retenir que les meilleures à la fin du processus.
Pour réussir cette dernière étape, nous avons créé différentes caractéristiques telles que la comparaison des réponses entre elles ou encore un score de confiance de la réponse à la question. Nous entraînons un XGBoost qui va prédire - avec une probabilité plus ou moins élevée - que la réponse renvoyée est bonne. Cela nous permet de ne renvoyer que les meilleures réponses et un score de confiance associé.
Human In The Loop (étape 8)
Comme mentionné précédemment, aucun exemple n'était nécessaire pour le moment. car la problématique est encore entièrement non supervisée, et cela peut être suffisant pour certains datapoints. Cependant, nous n'utilisons pas l'expertise humaine, qui est toujours précieuse dans certains cas d'usages très spécifiques.
Si la méthode non supervisée n'est pas suffisante, il est alors possible de passer à la méthode supervisée. En effet, l'utilisateur a la possibilité d'alimenter l'algorithme avec des exemples directement sur la plateforme pour l'entraîner, offrant ainsi de meilleurs résultats.
Lorsqu'une réponse correcte est validée par l'utilisateur, la valeur et le contexte entourant la réponse sont envoyés à la base de données, et seront utilisés pour entraîner un modèle qui sera plus efficace et plus ciblé lors de la prochaine extraction. Cette méthode hybride nous permet d'améliorer considérablement la précision. Cette étape est appelée "Human in the Loop".
Conclusion
Doc Review est un outil complexe d'apprentissage automatique capable d'extraire des informations clés de documents. Plusieurs approches de computer vision et de NLP ont été utilisées et combinées entre elles afin d'atteindre nos objectifs. L'association de l'apprentissage automatique supervisé et non supervisé permet à l'utilisateur d'obtenir d'excellents résultats sans fournir de base de données, puis d'améliorer la précision et la spécificité de l'algorithme lorsqu'il utilise la partie supervisée. Les modèles d'OCR développés permettent également à Doc Review de travailler sur des scans de faible qualité.
Nos clients et consultants utilisent cet outil d'IA hybride et flexible grâce à une application facile d’accès et la possibilité de poser des questions en langage naturel. Ils traitent les documents avec une plus grande efficacité et extraient des informations précieuses à partir de documents non structurés.
Si vous souhaitez en savoir plus sur notre solution, veuillez nous contacter.


