A journey to state of the art performances in topic analysis: Topic detection
This article tackles the methods that are currently most useful to address Topic detection and classification.
Introduction
There are several approaches and techniques for automatically analyzing topics in a text pool. Choosing one of them depends on the problem to be solved.
As we saw in the previous article of our trilogy, topic modeling is what you want if you have a set of texts and you want to determine the topics covered by these.
On the other hand, if you already know the possible topics for your texts and wish to automatically label them with the relevant topic, you want to make topic detection/classification.
This article tackles the methods that are currently most useful to address Topic detection and classification - a field of Natural Language Processing aiming at automatically tagging texts with a certain topic from predefined set, that can be built either using unsupervised topic modeling, or just from a prior knowledge of the main topics of our documents.
To demonstrate that, and as in Part 1, our working dataset is still linked to delivery services and comprises more than 10,000 Google reviews which cannot consistently be analyzed solely by humans, even if they are relatively short (limited to 4,000 characters). As for the targets, we have 14 topics that address important issues concerning delivery agencies, such as hours of operation, quality of service, shipping problems…
Supervised machine learning to save the day
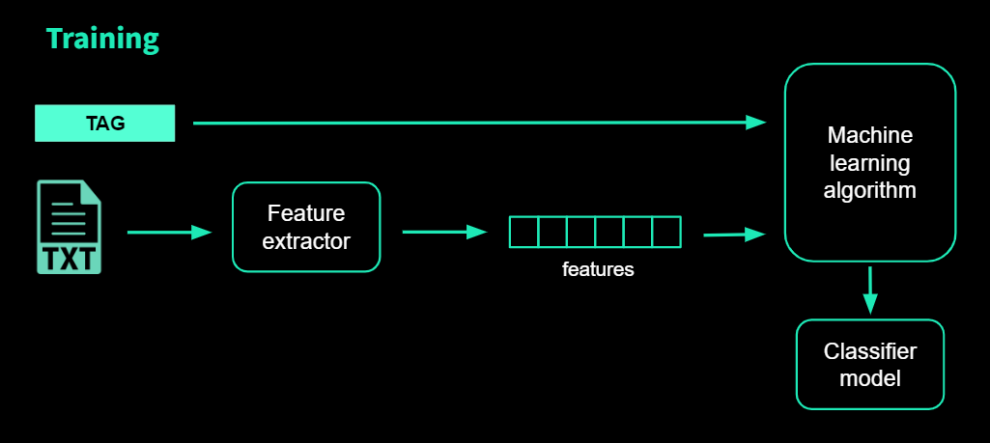
Unlike topic modeling algorithms, topic classification machine learning algorithms are supervised. This means you must provide them with documents that have already been labeled by topic, and the algorithms will learn to label new, previously unseen documents with those topics.
As a result, the topic definition and labeling processes are critical and should not be overlooked, as they determine the model's performance in real life.
However, the benefits of supervised algorithms easily outweigh the disadvantages. You can fine-tune your criteria and define your themes, and if you are consistent in labeling your texts, you will be rewarded with a model that will classify new, previously unseen samples based on your predefined topics, the same way that you would.
Evaluation criteria
To judge the operability and improvability of the models we will train, we need to have regular and consistent ways to measure and compare the results. And the regular metrics to do that are the Accuracy, Precision and Recall, and the F1-score.
And in order to evaluate the performance of a model, we’ll need to let it categorize texts that you already know which topic category they fall under, on ideally an unseen test dataset, other than the one used during the training, but with the same distribution and topics proportions.
You could add this testing data to the final model to empower your model, but then you won’t know if it was actually better off without it. So to avoid this problem, we can use cross-validation. In cross-validation, we split the training dataset randomly into equally sized sets (for example 10 sets with 10% of the data each). For each one of these sets, you train a classifier with all the data that's not in this set and use this set as the standard to test your model.
Then, you build the final model by training with all the data, but the performance metrics you use for it are the average of the partial evaluations.
However, one of the major drawbacks of this method is that it is very time consuming when using large and complex models as in deep learning.
A deeper dive into Topic Classification methods
- Rules based systems
Before diving into machine learning algorithms, it's critical to understand that a topic classifier can be created entirely by hand, without the use of machine learning.
This can be performed by directly programming a set of hand-made rules based on the content of the text inputs that a human can use to discern between them. The idea is that by directly examining semantically relevant textual elements and any associated metadata, the rules can distinguish between the inputs on various topics by representing the codified knowledge. These rules each consist of a pattern and the associated prediction (topic in this case).
One of the most common ways to build the rules out of the detected patterns is Regex.
- Machine learning methods
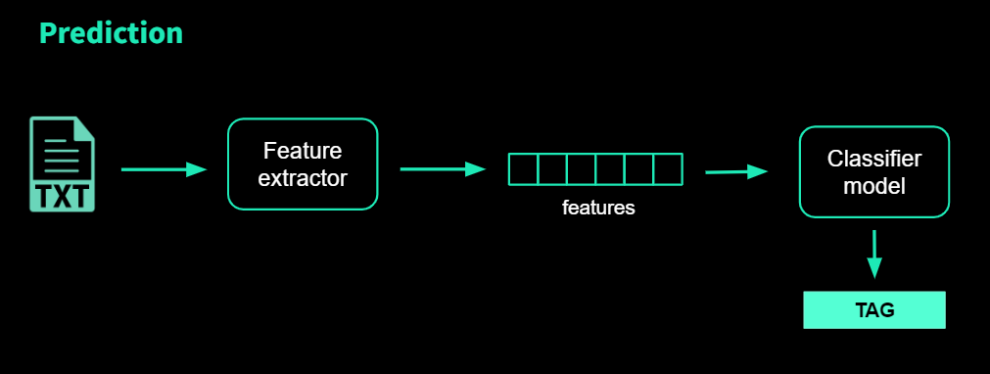
To train an NLP topic classification model in machine learning, text examples and the expected categories are fed as inputs. Then the model tries to identify patterns and classify the text into the categories you specify.
But first, training data must be converted into vectors, which are understandable to machines (i.e. lists of numbers which encode information). In order to learn from the training data and make predictions, the model can extract relevant information (features) using these numerical vectors.
The numerization can be accomplished in a variety of ways, and as we'll see later, deep learning can also be used to produce these embeddings.
- Combining Rules and Machine learning
Combining a basic machine learning classifier with a rule-based system that enhances the output with carefully chosen rules is the idea behind hybrid systems. These rules can be applied to topics that the base classifier failed to adequately model.
Our take on the problem
- A rule based model as a baseline (Regex)
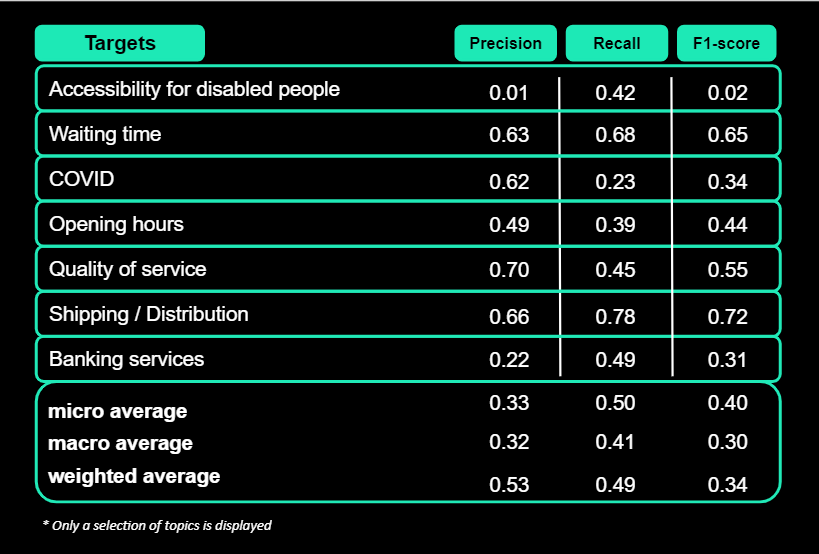
In order to obtain a baseline model to compare against during model development, we first explored the rule-based strategy by implementing Regex rules.
This simply involves collecting patterns for each topic, using expert inputs, and then converting them into Regex rules to cover them.
During prediction, if a verbatim contains a given pattern for a given topic, we tag it with this latter. This way, we can perform a multi-label classification.
The results for this strategy are as follows in the table below*:
- A machine learning approach
Sentence Transformers for the vectorization
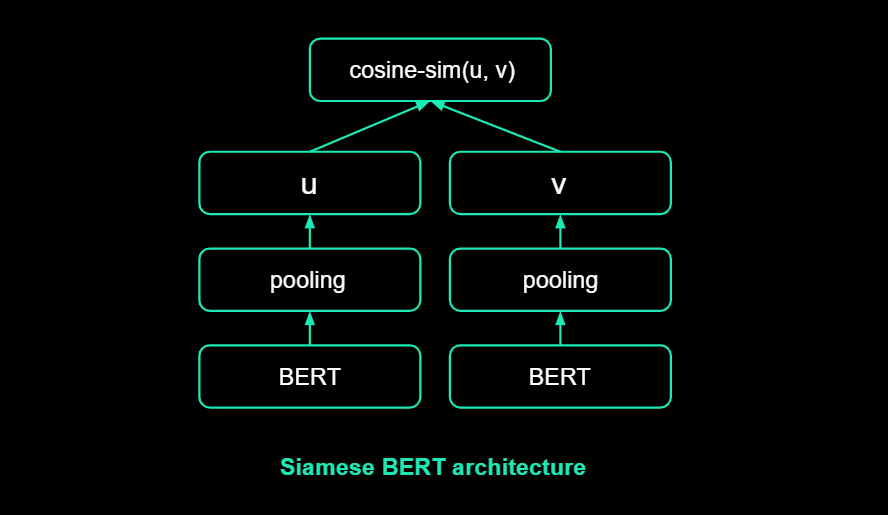
Sentence Transformer (ST) is a widely used approach for semantic search, similarity, and clustering. The goal is to encode a one-of-a-kind vector representation of a sentence based on its semantic signature. The representation is built during contrastive training by adapting a transformer model in a Siamese architecture, as shown in Figure below, with the goal of minimizing the distance between semantically similar sentences and maximizing the distance between semantically distant sentences.
Because they transform text into a structure of numeric values, STs can also be useful for other common NLP tasks like sentiment analysis and text classification. These tasks are then very simple to scale, manipulate, and process using pre-made Machine Learning (ML) models and popular frameworks.
And so, for all these reasons, we will use STs in our topic classification pipeline in our particular use case. The idea is to choose an ST model pre-trained on French or on several languages, and then use the numerical outputs of our dataset as input vectors to be classified by classical machine learning models. And to help us in our choice, we conducted a benchmark of the most popular STs to see which one fits the best to our problem, testing it directly on our data using a simple machine learning model as classifier. You can see the results in the table below:

- The Classifier
All we need now is a good multiple output classifier that we will place on top of our ST. As we mentioned, there is a very large choice of algorithms that we can apply once we have our numerical outputs: Naive Bayes, SVMs, Random Forests... Our intuition was to have a compromise between performance and speed to have a fast training/fine tuning to be able to improve our models and to have low inference times.
This is the main advantage of using this type of shallow models compared to other much more complex NLP deep learning algorithms.
The resurgence of universal transformers (BERT and its variants) has been extremely beneficial for text classification in general and topic classification in particular. But these techniques generally provide excellent results in exchange for expensive computational requirements. Deep learning models frequently train for days, weeks, or even months, and the model development phase can be quite challenging, especially if you need to deliver quickly.
SGD Classifier / Multi Output classifier
The SGD estimator implements regularized linear models (SVM, logistic regression, etc.) with stochastic gradient descent (SGD) learning: the gradient of the loss is estimated each sample at a time and the model is updated along the way with a decreasing learning rate.
For the features, his implementation works with data that is modeled as dense or sparse arrays of floating point values. And the loss parameter allows for control over the model it fits; by default, it fits a linear support vector machine (SVM).
However, these linear models do not natively support multi-target classification so to solve that we will use the MultiOutputClassifier from the scikit learn library. This strategy consists of fitting one classifier per target, enabling Multi target classification.
Training and Results
For the development and training of our model, and because the complexity of our model allows it, we used stratified cross-validation. This is important as when we divide our data into folds, we want to make sure that each fold accurately represents the entire data set. Especially in this case, where the classes are unbalanced.
Cross-validation also allows us to use all of our data and perform more efficient hyperparameter tuning on a single set.
The results of fitting our shallow estimator on the data, and testing it on the same test set used for validating the Regex base model, are as follow*:
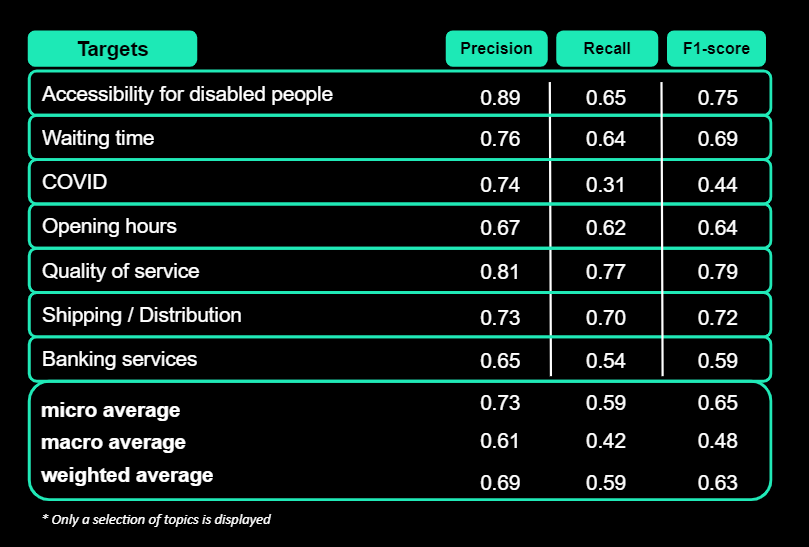
We can see a clear improvement of 25 points in the F1 micro score compared to the baseline. However, the performance of the model in some classes in particular suggests that we can imagine another way to even more increase the overall model performance…
Conclusion
Indeed, there are still several paths to explore in the Topic detection field to improve our model. We can imagine acting on the dataset (downsampling, upsampling, data augmentation) or on the objective function (Sample weighting) to achieve a more efficient training. Or stack the models or combine them according to their performance in each class to obtain a higher overall result.
Even so, this second step of our journey in the world of Topic Analysis allowed us to show the immense importance of having a prior knowledge of what our data contains, plus having expert inputs to guide the work of data scientists. This valuable information allows us to both use more SOTA and high performance models and save a lot of time trying to understand and examine the data in depth.
Learn more about topic modeling with our next article here.

