Synthetic data or how to share sensitive data while staying GDPR compliant
For a period of six months, 5 students from Centrale Supélec and ESSEC worked collaboratively with Sia Partners on building a Python library to create fake - which we'll call synthetic - data.
But what's the point of creating fake data? How could it help organizations?
In a context where the need for companies to handle personal data more securely is growing, along with the impressive development of Generative AI in the past months, this first article of a series of three runs you down synthetic data’s best practices. Whether you’re a data scientist, a company trying to be GDPR compliant, or a data enthusiast, let Sia Partners show you the world of synthetic data.
Stay tuned for the upcoming articles on specific use cases around synthetic data generation!
GDPR - a regulation that poses several challenges when it comes to sharing data
Most people have heard about the General Data Protection Regulation (GDPR) by now. It is generally well-known that this EU regulation is amongst the toughest privacy laws in the world, and poses several constraints on companies for collecting, storing, processing, and transferring personal data. However, what is less obvious is the implications for organizations and the actual frameworks they need to be put in place to keep the data safe.
In fact, in any business context where data must flow between parties (B2C or B2B) the GDPR has important implications.
For example, in a scenario where data is to be shared with a stakeholder for value, the client is considered as a “data controller” under the GDPR and determines the purpose for which the data can be used. The data services provider, on the other hand, is the “data processor” for the client’s data. In this context, the client takes responsibility for the stakeholder‘s compliance to GDPR when using the data. Additionally, the service provider must take ‘appropriate technical and organizational measures’1 to protect personal data, therefore the “data processor” also takes on more important responsibilities. Under the upcoming AI Act, the fine for failing this duty might be even more important than under the GDPR only. Given these increased risks, the client will naturally be less willing to share personal data with third parties. This could impede many stakeholders, like the data services provider who will face increased difficulty getting its hands on new data and thus unlocking potential use cases.
Thus, GDPR compliance can affect the bottom line in two ways. First, there is an increased difficulty for third parties to access client data needed to build appropriate proof of concepts (POCs) that facilitate value creation. Second, clients working with a specific third party can find it prohibitively difficult to change and restart the process of becoming GDPR compliant with another firm. In this way, the firm misses out on potential sources of activity and revenue.
So how can companies avoid all these issues and still benefit from external service providers?
Introducing Synthetic Data Generation: A Safer Way to Share Data while protecting customer privacy
The introduction of synthetic dataset generation has emerged as a promising solution to overcome this problem. By using algorithms to create artificial data that closely mirrors real data, synthetic data offers a form of anonymization that protects personal information. Some common anonymization techniques include :
- Data masking: removing or encrypting sensitive information
- Data pseudonymization: replacing sensitive information with different data. For example, a name could become a number
- Data generalization: keeping only general statistical information about the data
- Data perturbation: introducing some noise into the data
While these anonymization techniques may seem straightforward, they are not sufficient to protect privacy. In fact, in 2019, a team of researchers used generative AI to re-identify 99.98% of Americans in a de-identified dataset2 containing 15 attributes3.
Moreover, the challenge is to create anonymized data that remain interpretable for users while maintaining the same granularity as the original one. The techniques mentioned above generally alter data points in such a way that the output does not resemble the original data anymore and might sometimes be difficult to understand. Furthermore, the anonymization technique used must be scalable and efficient on datasets of all sizes, which is why encryption4 methods should be considered carefully.
Thus, to meet GDPR requirements when sharing data, creating synthetic data that is understood in the same way as real data, but that cannot be linked to specific individuals seems to be the most practical and safest way to go.
In practice
Synthetic data privacy-preserving generation is not a new concept. The idea of a fully synthesized dataset originates from the 90’s5 with the idea of fitting a joint multivariate probability distribution to the data and drawing samples from it. Although the statistical approach works well on simple datasets, in reality, the limited availability of complex statistical distributions alters the technique.
However, with the development of Generative AI, a number of other methods emerged. For example, Bayesian Networks generate synthetic data by making probabilistic inferences about variables’ values in a dataset given the values of the other variables 6. Nevertheless, it is only in the last ten years that the method really gained momentum, partly due to the advent of Variational Autoencoders (VAE)7 and Generative Adversarial Networks (GAN), allowing new ways artificial data generation.
GAN is the most frequently used technique for synthetic tabular data generation because of the diversity of artificial data it can create, and has already proved to be extremely useful for image generation and speech recognition. In this type of model, two neural networks compete against each other. The generator produces fake data to fool the discriminator that tries to differentiate between real and fake data. Both neural networks are trained iteratively until the discriminator is not able to accurately identify real data.
Schema explaining the principles of Generative Adversarial Networks (GANs)
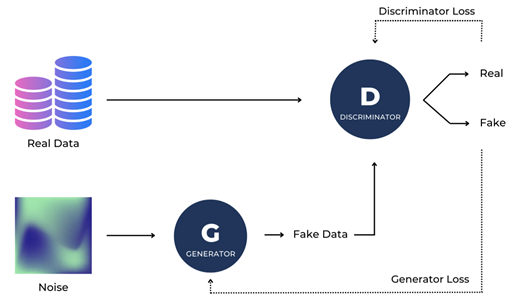
So, to create synthetic data, a model is trained on real data. Model draws are then used to replace the actual values and create the synthetic dataset that should be as interpretable as the original one: same key characteristics, attributes and correlations.
Datasets can be partially or fully synthesized, depending on the level of privacy-protection required. Any analysis performed or model trained on artificial data should yield the same results as when working with the original data. And all this while making it impossible to uncover the real data, enabling data sharing without risks of identity disclosure.
Some examples of companies using synthetic data include Amazon for training NLP models behind Alexa on new languages8, Waymo for training the driverless vehicle despite the lack of data due to lockdowns9 and La Mobilière for training their churn prediction algorithms without compromising their clients’ privacy10.
Overall, using synthetic data can reduce your time-to-data, save-up the time needed for evaluating data-confidentiality risks while maintaining similar performances on trained models.
Limitations
Although GANs allow to generate synthetic data very close to real data without revealing any information on individuals, certain limitations and privacy risks still exist.
First, there is an unavoidable trade-off between preserving privacy and ensuring that synthetic data is similar to the original data, especially when the data has many outliers. For example, we might want to synthesize a dataset containing all employees’ wages within a company. Even synthesized, if the fake data is too close to the real data, it will remain possible to link the highest salaries to the board of directors and thus re-identify individuals and disclose information about them. Generally, privacy-preserving synthetic data will never perfectly resemble the real data, although the closeness of the two datasets can usually be controlled, for example through the number of epochs.
Additionally, while the synthetic data can be freely shared without GDPR applying to it, it is important to consider that access to the model should be restricted. Indeed, through specific attacks such as the model inversion attack or membership inference attack, it is possible to uncover the original data used to train the model. Consequently, the model should preferably remain under the control of the data controller and be considered as sensitive information.
Use cases
Knowing all of this, Centrale Supélec and ESSEC students with the help of a dedicated team at Sia Partners are focusing on two case studies around which they are building the synthetic data generation library. The first case study focuses on creating synthetic data to improve fraud detection models while preserving subjects’ privacy. Fraud is an intentional deception to make unlawful gains, representing losses for companies. Fraud models aim to prevent it by identifying claims with high chances of being fraudulent in advance. However, as the frequency of fraud instances is generally much lower than honest claims, Machine Learning models often have trouble predicting it correctly. Creating synthetic fraud data can help improve models by rebalancing the dataset, allowing the fraud detection model to see more diverse examples of the anomaly it should be detecting. The challenge is therefore twofold, with both data augmentation and anonymization required.
The second case study is based on time series which are a very valuable type of data to synthesize. In fact, the chronological ordering of data points, like taxi rides, location data or credit card history, can truly behave like fingerprints. Synthesizing time series is also challenging, as the synthetic data must not only retain the same key characteristics and features distribution as in the original data at each time stamp, but also the general dynamics of the entities over time.
Conclusion
To protect the privacy of individuals, the GDPR requires data to be anonymized in order to be transferred and shared. Many straightforward anonymization techniques have existed for a long time and involved modifying the sensitive data to make it unlinkable to specific individuals. But what was once considered anonymous data, is no longer so: improvements in the field of computer science made it increasingly easy to re-identify subjects even from fully anonymized datasets. Nevertheless, impressive developments in the field of generative AI in the last decade have also allowed new anonymization techniques including synthetic data generation.
At Sia Partners, we have been collaborating with students from leading engineering and business schools on the development of GANs to generate privacy-preserving synthetic data, around two specific case studies. In the remaining articles of this series dedicated to synthetic data, we will go through GANs applications for improving and anonymizing fraud detection as well as for generating privacy-preserving time series.
[1] Citation from GDPR
[2] Data from which all personally identifiable information has been removed.
[3] Rocher, L, Hendrickx J., Montjoye, Y. Estimating the sucess of re-identifications in incomplete datasets using generative models. https://www.nature.com/articles/s41467-019-10933-3
[4] The process of transforming clear data into a hash code which only a key can make readable again. It is considered a computationally expensive method.
[5] Drechsler J, Haensch A. 30 years of synthetic data. Available at: https://arxiv.org/pdf/2304.02107v1.pdf
[6] Young, J., Graham, P, Penny, R. Using Bayesian Networks to Create Synthetic Data. Journal of Official Statistics, Vol. 25, №4, 2009, pp. 549–567. Available at: https://www.scb.se/contentassets/ca21efb41fee47d293bbee5bf7be7fb3/using-bayesian-networks-to-create-synthetic-data.pdf
[7] VAEs generate synthetic data by encoding it into a lower-dimensional latent space and decoding the representation back into the original input space.
[8]Tools for generating synthetic data helped bootstrap Alexa’s new-language releases : https://www.amazon.science/blog/tools-for-generating-synthetic-data-helped-bootstrap-alexas-new-language-releases
[9] The challenges of developing autonomous vehicles during a pandemic : https://venturebeat.com/ai/challenges-of-developing-autonomous-vehicles-during-coronavirus-covid-19-pandemic/
[10]Privacy preserving Machine Learning in insurance : La Mobilière success story : https://www.statice.ai/post/future-proofing-data-operations-successful-insurance-mobiliere

