
SiaGPT
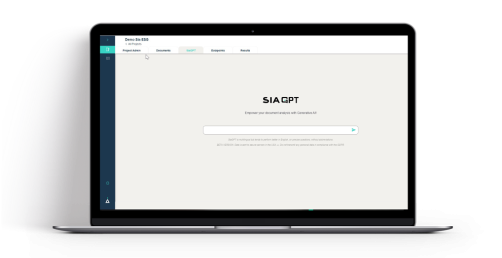
Support your business operations using Generative AI technology
Via a simple prompt interface, SiaGPT allows you to extract relevant information and generate unique content (insights, comparison…) based on your selection of a vast number of internal or external documents within your secure environment.
Functionalities
-
Main features
With one click, choose whether you want to work on live online data or your internal documents
Upload your documents / connect to your database in your secure environment
Manage, extract and compare information from uploaded documents

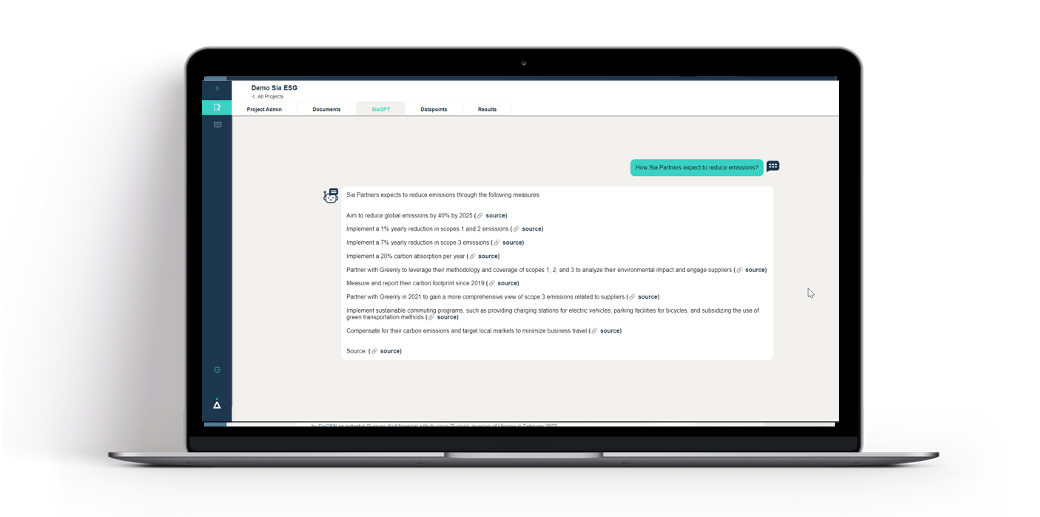
 Talk to SiaGPT using the chatbot to ask questions Generate information, comparative results, or mathematical calculations Track information by accessing the precise sources of the answers provided by SiaGPT in one click
Talk to SiaGPT using the chatbot to ask questions Generate information, comparative results, or mathematical calculations Track information by accessing the precise sources of the answers provided by SiaGPT in one click
Key Benefits
Search only the documents you choose to upload
Use capabilities from multiple LLMs in multiple languages
-
Increase productivity in data collection and reporting
Find information quickly within numerous documents
-
Develop an easy first use case for Generative AI
Streamline the management of your supplier contracts
-
Compare your metrics against peers or competitors
Summarise large volumes of information
SiaGPT


