
Smart Data Quality
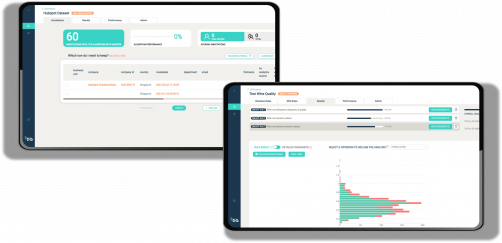
Improve your data quality
Let AI detect your duplicates, clean, complete, and enrich your data within a single solution.
Functionalities
- Deduplication
- Outlier detection
- Normalization on a sizable functional perimeter (address, bank details, customer details, etc.)
-
Leverage the power of machine learning
Let AI adjust processing to your context and optimize your automatic processing with the annotation tool.


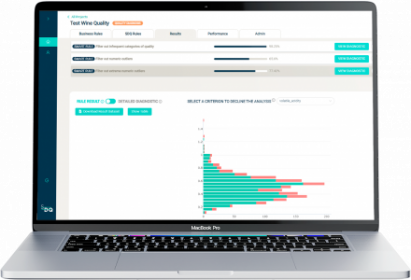
 Turn your data into opportunities: enrich it with other sources of information (internal data, open data, etc.) to better target your prospects or interventions, imagine new offers, develop operational performance, etc.
Turn your data into opportunities: enrich it with other sources of information (internal data, open data, etc.) to better target your prospects or interventions, imagine new offers, develop operational performance, etc.
Increase your data quality
Find all the data quality features:

Have a look at Smart Data Quality
Mobilizing your data has never been easier
-

Better accuracy
Diagnostic accuracy of 95%.
-

Optimized integration
Data quality processing is generated in a few clicks and natively integrating your business rules
-

A full interfacing service
Compatible with your existing tools
THEY TRUST US
-
UTILITIES COMPANY
We cleaned up the customer database as part of a CRM migration by deploying Smart Data Quality, a solution by Sia Partners, on AWS Cloud.
-
ENERGY DISTRIBUTOR
We enriched customer data with Open Data to refine customer segmentation.
-
GAS SUPPLIER
We enriched their data with those of social landlords to identify social housing and prioritize the maintenance of connections on its network.
-
WATER NETWORK OPERATOR
We enriched customer data with median incomes, household composition, and garden sizes to better understand water consumption and design new service offerings accordingly.


