Transform your document base into exploitable structured data
With Doc Review, upload your documents, ask questions and get answers
Introduction
In an increasingly digital world, it has been shown that 80% of company information remains in unstructured documents such as contracts, invoices, purchase orders or notes. The process of these documents is often done manually. It is time consuming, expensive and prone to human error.
Doc Review is an AI-based solution to automatically read thousands of documents and to extract key information that lies in them in an unstructured manner. This ability to process large amounts of documents on a variety of business cases helps our customers to solve this problem. For example, by analyzing more than 8000 collective agreements automatically, Doc Review helped a major French newspaper conduct a study on the rise of remote working in France. We also helped an insurance company add thousands of old paper contracts in their brand new CRM tool.
Breakthrough in the field of Natural Language Processing
Heka, the ecosystem of Artificial Intelligence solutions developed by Sia Partners, has often been contacted for this kind of mission. Until recently, it was difficult to make a tool able to answer those various use cases:
- Documents come in all shapes and sizes
- Information to be extracted depends on the client and his business case
- Diversity in the information sought makes it impossible to have a single model
Today, the lightning progress in the field of artificial intelligence and particularly in the field of Natural Language Processing with models such as BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding) or the rise of Question Answering now allows us to meet this challenge. No matter the type of document or its format, coming from a poorly scanned document (image of pdf) to a valuable piece of information, these are the typical use cases we tried to tackle.
General Structure of Doc Review
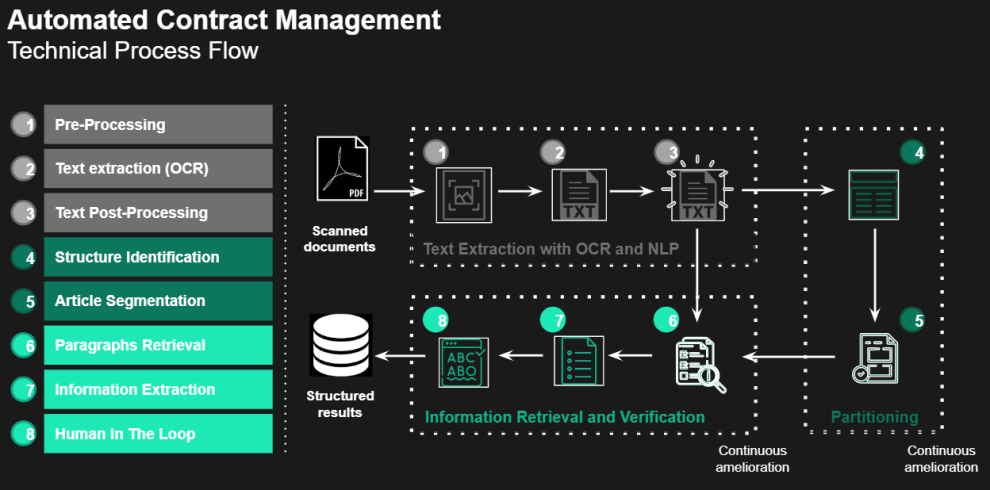
In the following sections, we will present the eight different steps we developed to achieve our goal - to extract information written in natural language in an unstructured document .
To illustrate this, we will take a contract such as this one (collective agreement) as an example. The datapoint - key piece of information - we are going to extract will be the governing law of this contract (section 6.4 Governing law).
In order to achieve this process, the inputs needed are the scanned document and a query. The document is a 56-page long contract and the query is a simple question asked in natural language as one would ask to a human being: Under what laws shall this agreement be governed?
Doc Review reads and transcripts automatically thanks to our in-house OCR (Step 1-2-3)
The first step to read a document is to perform an Optical Character Recognition (OCR). An OCR is the process of extracting the text of an image. The quality of the extraction will obviously depend on the quality of the image. It is therefore up to us to preprocess the image so the OCR will perform under the best conditions.
Different steps need to be taken into account:
- Detection and correction of skewness
- Automation of color processing for non black & white docs
- Binarization to remove blurs and noise
- Correction of uneven background (e.g. watermarks, smudges)
- Detection and extraction of tables object

Extracting the text from the image is the first step, but keeping the structure of the document is even more useful.
Doc Review keeps the structure of the document - (Step 4-5)
The goal here is to keep track of the document’s structure. Identifying titles, subtitles, which paragraph belongs to which section can be useful not only for the user to navigate through the document, but also to extract datapoints. If Doc Review can identify an article title such as "Governing Law", then there is a good chance that the datapoint value we are looking for is in that paragraph.
To keep track of the structure, we need to remove the noise in the document. The first step is to identify the type of page, whether it is a cover page, a table of contents, a contract page. Then, we need to distinguish the header/footer on the page from the actual text, the same goes for the page number.
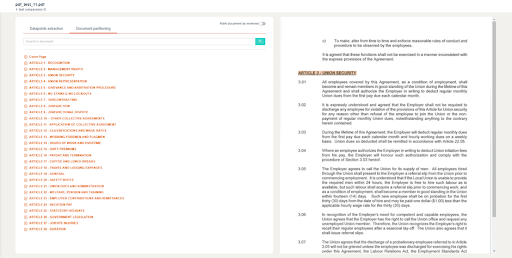
Result is a perfectly readable and tidy document transcription we named “Document Partitioning”. Users can benefit from this functionality directly through the user interface. As you can see on figure 3, the right part represents the original pdf, the left part represents the segmentation made by Doc Review.
Doc Review extracts key information thanks to NLP (Step 6-7)
Like every machine learning problem, the first step before modelling is to identify the type of challenge : supervised or unsupervised machine learning?
Extracting the governing law of a contract that we have never seen before is unsupervised learning, leaving us with the question: how do we extract a datapoint from an unknown document without any labelled examples?
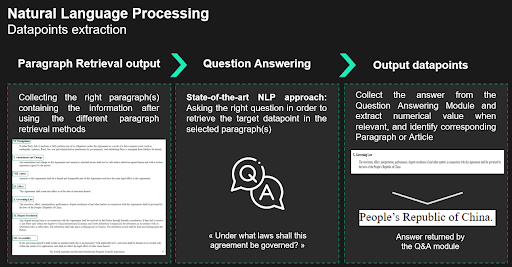
The algorithm will proceed just as an analyst would. First, have a glance at the document, and retrieve paragraphs where the answer might lie. Second, read closely the retrieved paragraphs to extract the answer. In NLP terms, the first step is called paragraph retrieval and the second step, question answering.
Paragraph retrieval using document partitioning
The first approach to retrieve candidate paragraphs would be to leverage the document partitioning. One can imagine the document as a dictionary where the key would be the name of the article, and the value is the associated paragraph. When keywords or article names are provided, we can match those inputs with articles names to draw a list of candidate paragraphs. Then we run the question answering module on the identified paragraph.

Paragraph retrieval using Dense Passage Retrieval
The previous approach, when provided with article names or keywords, indeed works. But what if the user has no idea of such inputs?
This is where the Dense Passage Retrieval1 (DPR) comes into play. The DPR consists of two parts: a retriever and a reader. The DPR algorithm will take as input a query - a question in natural language about the clause we want to retrieve, for example Under what laws shall this agreement be governed? - and a raw text, output of the OCR.
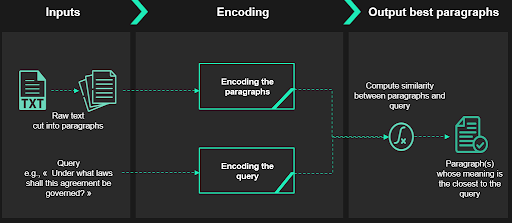
The retriever will split the provided text into paragraphs. Then it will embed these paragraphs along with the query (with the same embedding). It will then measure the cosine similarity of a paragraph and the query and finally rank them.
The reader - which can be likened to a question answering module - will then go over the closest (in terms of cosine similarity) paragraphs returned by the retriever to extract the final answer.
Ranking
Finally, we have different answers coming from different methods. The last step is to find a way to classify those answers in order to come up only with the best ones at the end of the process.
To succeed, we created different features such as the comparison of answers between them or a confidence score from the question answering. We train an XGBoost that will predict - with a higher or lower probability - that the returned answer is a good one. This allows us to return only the best answers and an associated confidence score.
Human in the loop (Step 8)
As mentioned earlier, no examples were needed at this time. The problem is still fully unsupervised, and this may be enough on some datapoints. However, we do not use human expertise, which is always valuable for very specific use cases.
If the unsupervised method is no longer sufficient, it is then possible to switch to the supervised method. Indeed, the user has the possibility to feed examples to the algorithm directly on the platform to be trained offering better results.
When a correct answer is validated by the user, the value and the context surrounding the answer are sent to the database, and will be used to train a model that will be more efficient and more targeted during the next extraction. This hybrid method allows us to significantly upgrade the accuracy. This step is called Human in the Loop.
Conclusion
Doc Review is a complex machine learning tool able to extract key information from documents. Several approaches of computer vision and NLP had to be used and combined in order to reach our goals. The association of unsupervised and supervised machine learning allows the user to have great results without providing any database, and then improves accuracy and specificity of the algorithm when using the supervised part. The custom OCR models developed also allow Doc Review to work on low quality scans.
Our customers and consultants are using this hybrid and flexible AI tool thanks to a user-friendly interface and the capability to ask questions in natural language. They process documents with greater efficiency and unlock valuable information from unstructured documents.
If you want to know more about our solution, please contact us.

